前言
这些自定义的文本函数弥补了DAX语言对文本处理的不足,提供了常用的文本处理函数,包括清洗、提取、转换和重组文本数据等。
使用方式
方式一:DAX查询
复制以下DAX查询代码,粘贴到PowerBI的查询视图中运行,即可导入文本函数库。
关于每个函数的具体语法与介绍,请参考左边菜单栏的具体函数页面。
DEFINE
/// 从字符串中返回第N个位置的分隔符后的文本,分隔符位置从1开始
FUNCTION XF.Str.AfterDelimiter = (str:string,delimiter:string,n:int64) =>
IF(n>=1,
VAR SplitedKey = "虪"
VAR AlterText = SUBSTITUTE(str,"|",SplitedKey)
VAR AlterDelimiter = SUBSTITUTE(delimiter,"|",SplitedKey)
VAR TransToPath = SUBSTITUTE(AlterText,AlterDelimiter,"|")
RETURN
CONCATENATEX(
ADDCOLUMNS(
GENERATESERIES(n+1,PATHLENGTH(TransToPath)),
"SubStr",SUBSTITUTE(PATHITEM(TransToPath,[Value]),SplitedKey,"|")
),
[SubStr],
delimiter,
[Value],ASC
),
ERROR("分隔符位置应大于或等于1")
)
/// 从字符串中返回指定索引位置的字符,索引位置从1开始
FUNCTION XF.Str.AtIndex = (str:string,index:int64) =>
IF(index>=1,
MID(str,index,1),
ERROR("索引应大于或等于1")
)
/// 从字符串中返回第N个位置的分隔符前的文本,分隔符位置从1开始
FUNCTION XF.Str.BeforeDelimiter = (str:string,delimiter:string,n:int64) =>
IF(n>=1,
VAR SplitedKey = "虪"
VAR AlterText = SUBSTITUTE(str,"|",SplitedKey)
VAR AlterDelimiter = SUBSTITUTE(delimiter,"|",SplitedKey)
VAR TransToPath = SUBSTITUTE(AlterText,AlterDelimiter,"|")
RETURN
CONCATENATEX(
ADDCOLUMNS(
GENERATESERIES(1,MIN(n,PATHLENGTH(TransToPath))),
"SubStr",SUBSTITUTE(PATHITEM(TransToPath,[Value]),SplitedKey,"|")
),
[SubStr],
delimiter,
[Value],ASC
),
ERROR("分隔符位置应大于或等于1")
)
/// 从字符串中返回指定分隔符中间的文本,可使用startIndex参数指定使用第几个起始分隔符,endIndex参数则指定使用第几个结束分隔符,只不过endIndex的起始位置是相对于startIndex后的
FUNCTION XF.Str.BetweenDelimiters = (str:string,startDelimiter:string,endDelimiter:string,startIndex:int64,endIndex:int64) =>
IF(startIndex<1 || endIndex<1,
ERROR("startIndex and endIndex should >=1"),
VAR StartDelimiterIndex =
DISTINCT(
FILTER(
SELECTCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Position",FIND(startDelimiter,str,[Value],BLANK())
),
[Position]<>BLANK()
)
)
VAR StartDelimiterIndex_AddRank =
ADDCOLUMNS(
StartDelimiterIndex,
"Rank",RANKX(StartDelimiterIndex,[Position],,1)
)
VAR StartIndex = COALESCE(MAXX(FILTER(StartDelimiterIndex_AddRank,[Rank]=startIndex),[Position]),LEN(str))
VAR RightText = RIGHT(str,MAX(LEN(str)-(StartIndex+LEN(startDelimiter)-1),0))
VAR SplitedKey = "虪"
VAR Alter_RightText = SUBSTITUTE(RightText,"|",SplitedKey)
VAR Alter_EndDelimiter = SUBSTITUTE(endDelimiter,"|",SplitedKey)
VAR TransToPath = SUBSTITUTE(Alter_RightText,Alter_EndDelimiter,"|")
RETURN
CONCATENATEX(
ADDCOLUMNS(
GENERATESERIES(1,MIN(endIndex,PATHLENGTH(TransToPath))),
"SubStr",SUBSTITUTE(PATHITEM(TransToPath,[Value]),SplitedKey,"|")
),
[SubStr],
endDelimiter,
[Value],ASC
)
)
/// 从字符串中清除所有控制字符或零宽不可见字符
FUNCTION XF.Str.Clean = (str:string) =>
CONCATENATEX(
FILTER(
GENERATE(
GENERATESERIES(1,LEN(str)),
VAR Char = MID(str,[Value],1)
RETURN
ROW("Char",Char,"Unicode",UNICODE(Char))
),
VAR IsRemove =
[Unicode] < 32
|| ([Unicode] >= 127 && [Unicode] <= 159) // 控制字符
|| [Unicode] IN {8203,8204,8205,8232,8233,8288,65279} // 零宽 段分隔 BOM等
RETURN
NOT IsRemove
),
[Char],
"",
[Value],ASC
)
/// 返回指定字符串末尾的N个字符
FUNCTION XF.Str.Ends = (str:string,n:int64) => RIGHT(str,n)
/// 判断字符串是否以指定的文本结尾,IsExact参数的值:1:区分大小写,0:不区分大小写
FUNCTION XF.Str.EndsWith = (str:string,endText:string,isExact:int64) =>
IF(NOT isExact IN {0,1},
ERROR("IsExact参数的可选取值仅为0或1"),
VAR EndStr = RIGHT(str,LEN(endText))
RETURN
SWITCH(
isExact,
1,CONTAINSSTRINGEXACT(EndStr,endText),
0,CONTAINSSTRING(EndStr,endText)
)
)
/// 将指定文本插入到字符串的指定索引位置,索引位置从1开始
FUNCTION XF.Str.InsertText = (str:string,index:int64,newText:string) =>
IF(index>=1,
REPLACE(str,index,0,newText),
ERROR("索引应大于等于1")
)
/// 判断指定字符串中是否包含另一个字符串,IsExact参数的值:1:区分大小写且不支持通配符,0:不区分大小写且可使用?与*通配符
FUNCTION XF.Str.IsContains = (str:string,findText:string,isExact:int64) =>
IF(NOT isExact IN {0,1},
ERROR("IsExact参数的可选取值仅为0或1"),
SWITCH(
isExact,
1,CONTAINSSTRINGEXACT(str,findText),
0,CONTAINSSTRING(str,findText)
)
)
/// 检查值是否为文本
FUNCTION XF.Str.IsText = (val:anyval) => ISTEXT(val)
/// 返回指定字符串的字符数量,即文本长度
FUNCTION XF.Str.Length = (str:string) => LEN(str)
/// 将字符串中的所有字符改为小写
FUNCTION XF.Str.Lower = (str:string) => LOWER(str)
/// 若字符串长度小于指定长度,则在字符串的末尾填充指定字符直到达到指定长度,否则返回原字符串
FUNCTION XF.Str.PadEnd = (str:string,length:int64,char:string) =>
IF(LEN(char)<>1,
ERROR("填充字符参数必须为单个字符"),
str&REPT(char,MAX(length-LEN(str),0))
)
/// 若字符串长度小于指定长度,则在字符串的起始填充指定字符直到达到指定长度,否则返回原字符串
FUNCTION XF.Str.PadStart = (str:string,length:int64,char:string) =>
IF(LEN(char)<>1,
ERROR("填充字符参数必须为单个字符"),
REPT(char,MAX(length-LEN(str),0))&str
)
/// 返回字符串中的指定文本的出现位置,searchMode参数:0:返回第一次出现的位置索引,1:返回最后一次出现的位置索引,2:以表的形式返回所有出现的位置索引;索引位置从1开始
FUNCTION XF.Str.PositionOf = (str:string,findText:string,searchMode:int64) =>
VAR AllPosition =
DISTINCT(
FILTER(
SELECTCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Position",FIND(findText,Str,[Value],BLANK())
),
[Position]<>BLANK()
)
)
VAR MinPosition = MINX(AllPosition,[Position])
VAR MaxPosition = MAXX(AllPosition,[Position])
RETURN
FILTER(
AllPosition,
SWITCH(
searchMode,
0,MinPosition=[Position],
1,MaxPosition=[Position],
2,TRUE(),
ERROR("searchMode参数的可选取值仅为:0、1、2")
)
)
/// 将字符串的每个单词的首字符转为大写,其他字符转为小写
FUNCTION XF.Str.Proper = (str:string) =>
VAR lstr = LOWER(str)
VAR CalKey = "AWASDQ~SCD!~@)SD"
RETURN
SUBSTITUTE(
CONCATENATEX(
GENERATE(
GENERATESERIES(1,LEN(lstr)),
VAR Cur = MID(lstr,[Value],1)
VAR Pre = IF([Value]>1,MID(lstr,[Value]-1,1))
VAR IsLetter_Cur = NOT CONTAINSSTRINGEXACT(UPPER(Cur),LOWER(Cur))
VAR IsLetter_Pre = IF([Value]=1,FALSE(),NOT CONTAINSSTRINGEXACT(UPPER(Pre),LOWER(Pre)))
VAR Out = IF(IsLetter_Cur && ([Value]=1 || NOT IsLetter_Pre),UPPER(Cur),Cur&CalKey)
RETURN
ROW("Out",Out,"Cur",Cur,"Pre",Pre,"is_Cur",IsLetter_Cur,"is_Pre",IsLetter_Pre)
),
[Out],
"",
[Value],ASC
),
CalKey,
""
)
/// 从指定位置处开始,返回N个字符的子字符串,索引位置从1开始
FUNCTION XF.Str.Range = (str:string,startIndex:int64,n:int64) => MID(str,startIndex,n)
/// 从字符串中删除指定的所有字符,区分大小写;removeChars参数是一个字符串,该字符串内的每个字符就是要删除的指定字符
FUNCTION XF.Str.Remove = (str:string,removeChars:table) =>
CONCATENATEX(
FILTER(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1)
),
NOT CONTAINSSTRINGEXACT(removeChars,[Char])
),
[Char],
"",
[Value],ASC
)
/// 从指定位置处开始,删除N个字符,返回删除后的字符串,索引位置从1开始
FUNCTION XF.Str.RemoveRange = (str:string,startIndex:int64,n:int64) => REPLACE(str,startIndex,n,"")
/// 将指定的字符串重复N次
FUNCTION XF.Str.Repeat = (str:string,n:int64) => REPT(str,n)
/// 将字符串中的所有指定文本替换成新文本,可使用Position参数指定仅替换第几个位置的文本,索引位置从1开始,0代表替换所有
FUNCTION XF.Str.Replace = (str:string,old:string,new:string,position:int64) =>
IF(position=0,
SUBSTITUTE(str,old,new),
SUBSTITUTE(str,old,new,position)
)
/// 从指定位置处开始,将N个字符的子字符串替换成新文本,索引位置从1开始
FUNCTION XF.Str.ReplaceRange = (str:string,startIndex:int64,n:int64,newText:string) => REPLACE(str,startIndex,n,newText)
/// 将给定的字符串进行反转,返回反转后的字符串
FUNCTION XF.Str.Reverse = (str:string) =>
CONCATENATEX(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1)
),
[Char],
"",
[Value],DESC
)
/// 从字符串中删除未指定的所有字符,即只保留指定的字符,区分大小写;selectChars参数是一个字符串,该字符串内的每个字符就是要保留的指定字符
FUNCTION XF.Str.Selects = (str:string,selectChars:string) =>
CONCATENATEX(
FILTER(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1)
),
CONTAINSSTRINGEXACT(selectChars,[Char])
),
[Char],
"",
[Value],ASC
)
/// 按指定分隔符拆分字符串,返回Index与SubStr两列的表,其中Substr即为各个拆分后的子字符串,Index为顺序索引
FUNCTION XF.Str.Split=(str:string,delimiter:string)=>
VAR SplitedKey = "虪"
VAR AlterText = SUBSTITUTE(str,"|",SplitedKey)
VAR AlterDelimiter = SUBSTITUTE(delimiter,"|",SplitedKey)
VAR TransToPath = SUBSTITUTE(AlterText,AlterDelimiter,"|")
RETURN
SELECTCOLUMNS(
GENERATESERIES(1,PATHLENGTH(TransToPath)),
"Index",[Value],
"SubStr",SUBSTITUTE(PATHITEM(TransToPath,[Value]),SplitedKey,"|")
)
/// 将指定文本的每个字符作为分隔符来拆分字符串,返回Index与SubStr两列的表,其中Substr即为各个拆分后的子字符串,Index为顺序索引
FUNCTION XF.Str.SplitAny=(str:string,delimiter:string)=>
VAR CurText = str
VAR DelimiterPositions =
SUMMARIZE(
GENERATE(
DISTINCT(
SELECTCOLUMNS(
GENERATESERIES(1,LEN(delimiter)),
"delimiterstr",MID(delimiter,[Value],1)
)
),
DISTINCT(
FILTER(
SELECTCOLUMNS(
GENERATESERIES(1,LEN(CurText)),
"Position",FIND([delimiterstr],CurText,[Value],BLANK())
),
[Position]<>BLANK()
)
)
),
[Position]
)
VAR SplitPositions =
UNION(
SELECTCOLUMNS({0},"Position",[Value]),
DelimiterPositions,
{LEN(CurText)+1}
)
VAR SplitPosition_AddIndex = ADDCOLUMNS(SplitPositions,"Index",RANKX(SplitPositions,[Position],,1))
RETURN
SELECTCOLUMNS(
GENERATESERIES(1,COUNTROWS(SplitPositions)-1),
"Index",[Value],
"SubStr",
VAR Start_ = SUMMARIZE(FILTER(SplitPosition_AddIndex,[Index]=[Value]),[Position])+1
VAR End_ = SUMMARIZE(FILTER(SplitPosition_AddIndex,[Index]=[Value]+1),[Position])
RETURN
MID(CurText,Start_,End_-Start_)
)
/// 返回指定字符串开始的N个字符
FUNCTION XF.Str.Starts = (str:string,n:int64) => LEFT(str,n)
/// 判断字符串是否以指定的文本开头,IsExact参数的值:1:区分大小写,0:不区分大小写
FUNCTION XF.Str.StartsWith = (str:string,startText:string,isExact:int64) =>
IF(NOT isExact IN {0,1},
ERROR("IsExact参数的可选取值仅为0或1"),
VAR StartStr = LEFT(str,LEN(startText))
RETURN
SWITCH(
isExact,
1,CONTAINSSTRINGEXACT(StartStr,startText),
0,CONTAINSSTRING(StartStr,startText)
)
)
/// 从字符串的起始与末尾两个方向删除指定的前导与尾随字符,区分大小写;TrimText参数是一个字符串,该字符串内的每个字符就是要删除的前导或尾随字符
FUNCTION XF.Str.Trim = (str:string,trimText:string) =>
VAR CleanIndex =
FILTER(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1),
"IsTrim",CONTAINSSTRINGEXACT(trimText,MID(str,[Value],1))
),
NOT [IsTrim]
)
VAR StartIndex = MINX(CleanIndex,[Value])
VAR EndIndex = MAXX(CleanIndex,[Value])
RETURN
MID(str,StartIndex,EndIndex-StartIndex+1)
/// 从字符串的起始方向删除指定的前导字符,区分大小写;TrimText参数是一个字符串,该字符串内的每个字符就是要删除的前导字符
FUNCTION XF.Str.TrimStart = (str:string,trimText:string) =>
VAR CleanIndex =
FILTER(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1),
"IsTrim",CONTAINSSTRINGEXACT(trimText,MID(str,[Value],1))
),
NOT [IsTrim]
)
VAR StartIndex = MINX(CleanIndex,[Value])
RETURN
RIGHT(str,LEN(str)-StartIndex+1)
/// 从字符串的末尾方向删除指定的尾随字符,区分大小写;TrimText参数是一个字符串,该字符串内的每个字符就是要删除的尾随字符
FUNCTION XF.Str.TrimEnd = (str:string,trimText:string) =>
VAR CleanIndex =
FILTER(
ADDCOLUMNS(
GENERATESERIES(1,LEN(str)),
"Char",MID(str,[Value],1),
"IsTrim",CONTAINSSTRINGEXACT(trimText,MID(str,[Value],1))
),
NOT [IsTrim]
)
VAR EndIndex = MAXX(CleanIndex,[Value])
RETURN
LEFT(str,EndIndex)
/// 将字符串中的所有字符改为大写
FUNCTION XF.Str.Upper = (str:string) => UPPER(str)方式二:外部工具
还可以使用配套的PowerBI外部工具来导入已发布的所有自定义函数,如下图所示:
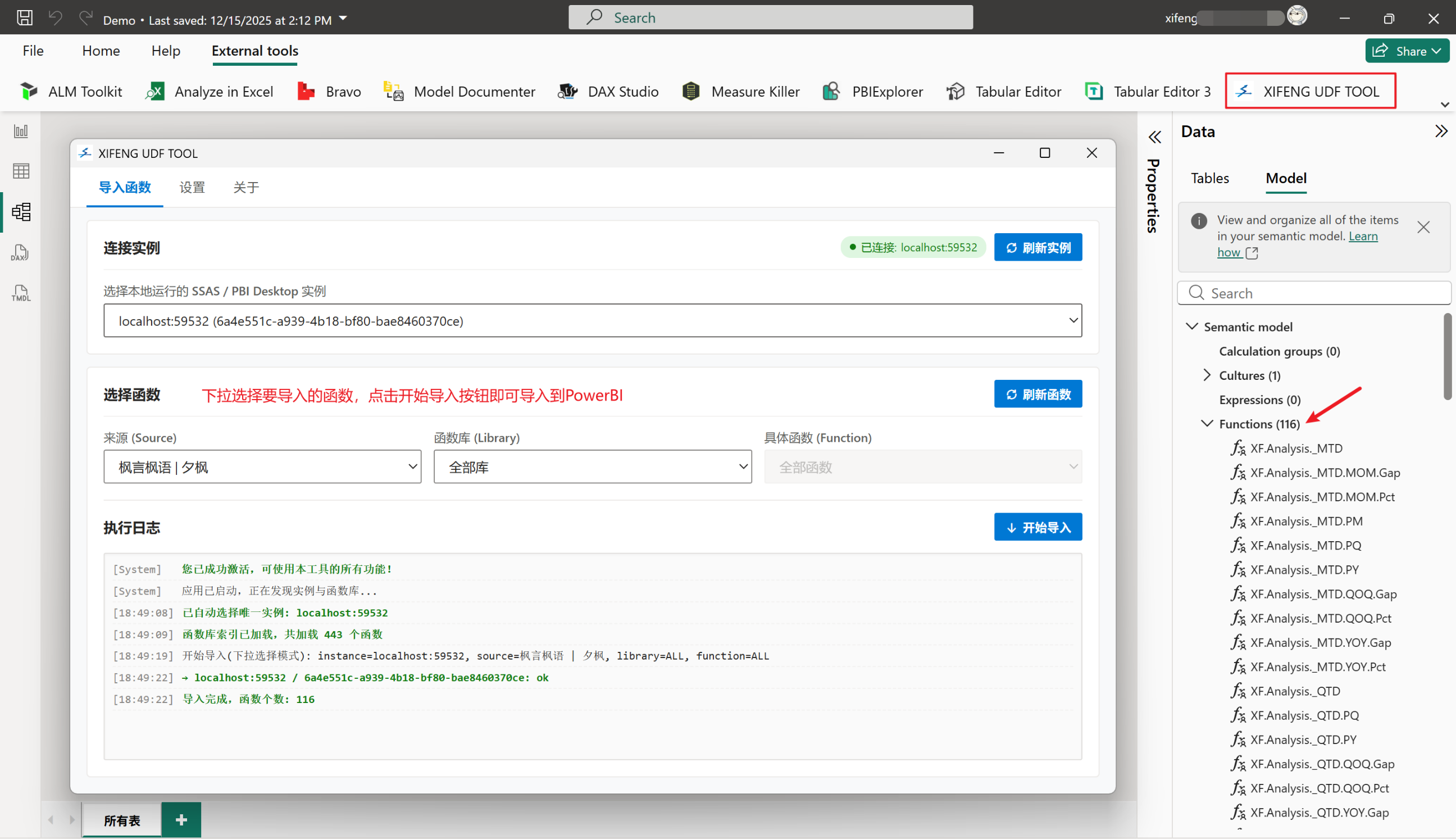
该外部工具会自动联网获取最新的DAX自定义函数列表,可搜索或选择要导入的DAX自定义函数,然后选择对应的PowerBI实例后,点击开始导入即可。
另外,该外部工具还支持导入SQLBI的DaxLib平台的函数,并支持本地函数库功能,而且除了下拉选择模式外还支持模糊搜索模式。
该外部工具的获取方式如下:
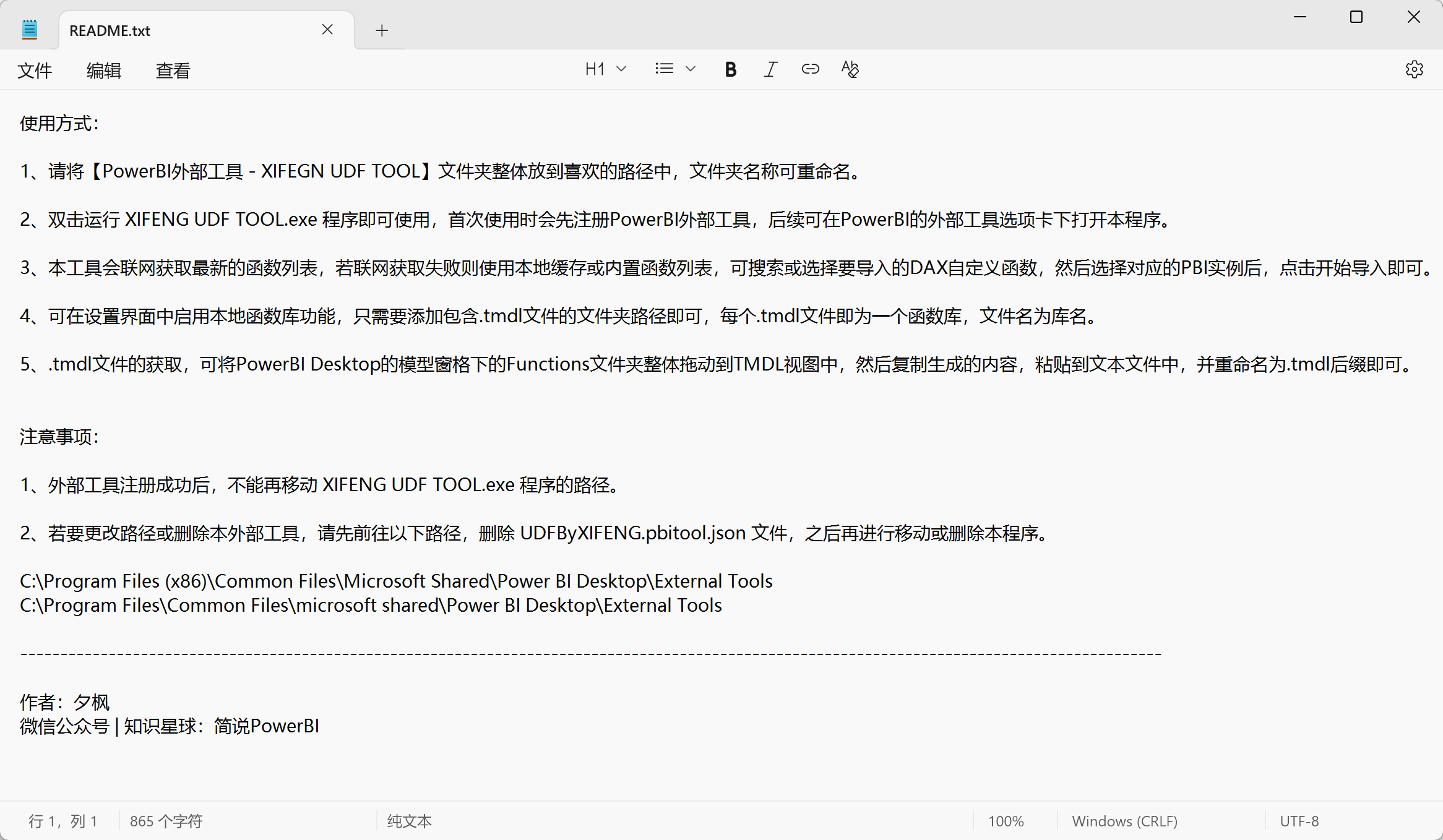
关于该外部工具的安装与使用方式,可阅读附带的 README.txt 文件,如下图所示:
其他
如果有任何问题或想法,欢迎在评论区提交你的需求与改进建议,一起完善该函数库!