
SUMMARIZE函数也是DAX的核心函数之一,它可以对表进行分组并添加派生列,可以很方便的对数据进行透视聚合。
语法和作用
语法:
SUMMARIZE (<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, <name>, <expression>]…)作用:对第一参数的表按指定的分组列进行分组,返回分组列的不重复组合形成的表,并可以往该表中添加派生列。
参数说明:
1、table,要进行分组的表,任意返回表的表达式
2、groupBy_columnName,要进行分组的列,必须来自第一参数的表或其扩展表
3、name,添加的派生列的列名
4、expression,添加的派生列的表达式,将在第一参数的表按分组列进行分组后的筛选上下文和分组列的行上下文中计值
注意事项:
1、分组列必须来自第一参数的表,否则会报错。
2、若第一参数的表存在扩展表,那么第二参数的分组列可以是其扩展表上的任意列。
3、派生列的计值环境中同时存在筛选上下文和行上下文,其中行上下文由分组列提供,筛选上下文则是第一参数的表在当前分组区间内的值形成的固化筛选器。
辅助理解的例子
首先,用到的数据源只有一张表,如下图所示:

1、不添加派生列,使用SUMMARIZE函数返回分组列的不重复组合形成的表,如下图所示:
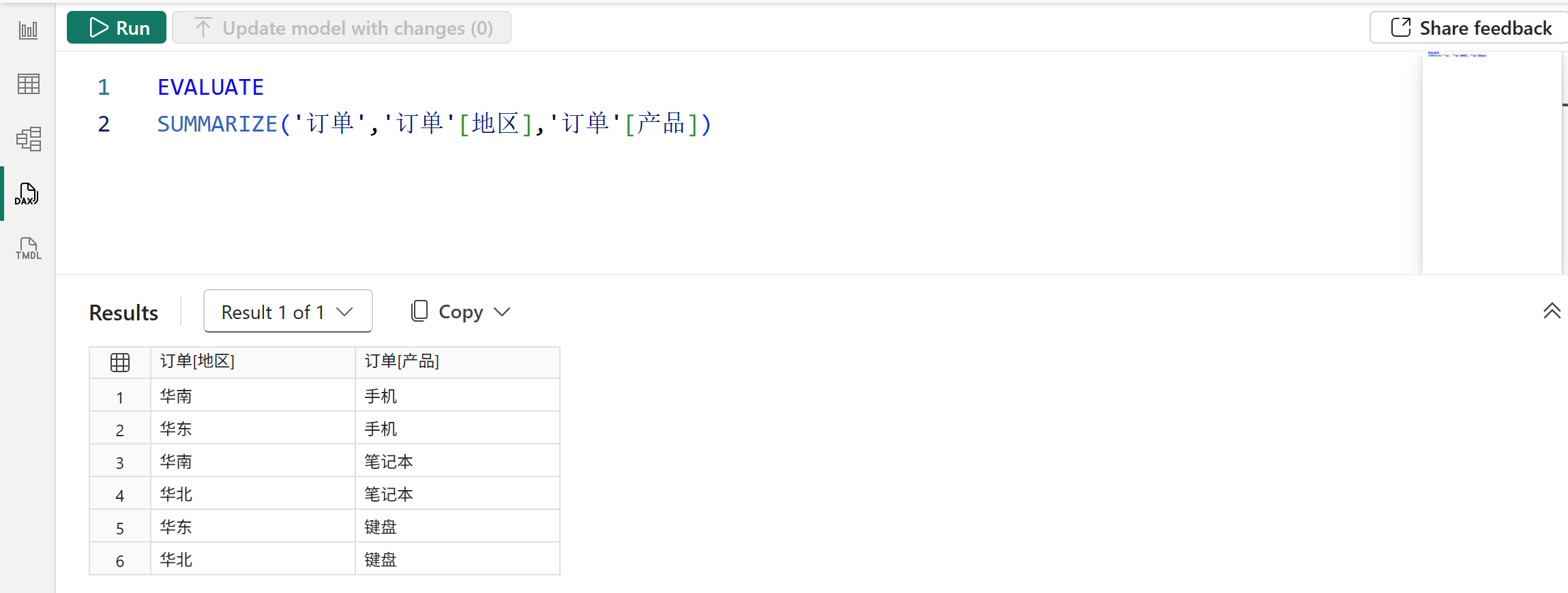
由于没有添加派生列,此时SUMMARIZE函数的行为就是从第一参数的表中提取分组列参数所指定的字段,然后进行去重。为方便理解,如果用其他函数来表达的话,其行为等价于以下表达式:
SUMMARIZE('订单','订单'[地区],'订单'[产品])
等价于:
DISTINCT(SELECTCOLUMNS('订单','订单'[地区],'订单'[产品]))2、SUMMARIZE函数的派生列的计值环境同时存在筛选上下文和行上下文,其中行上下文由分组列提供,筛选上下文则是第一参数的表在当前分组区间内的值形成的固化筛选器。
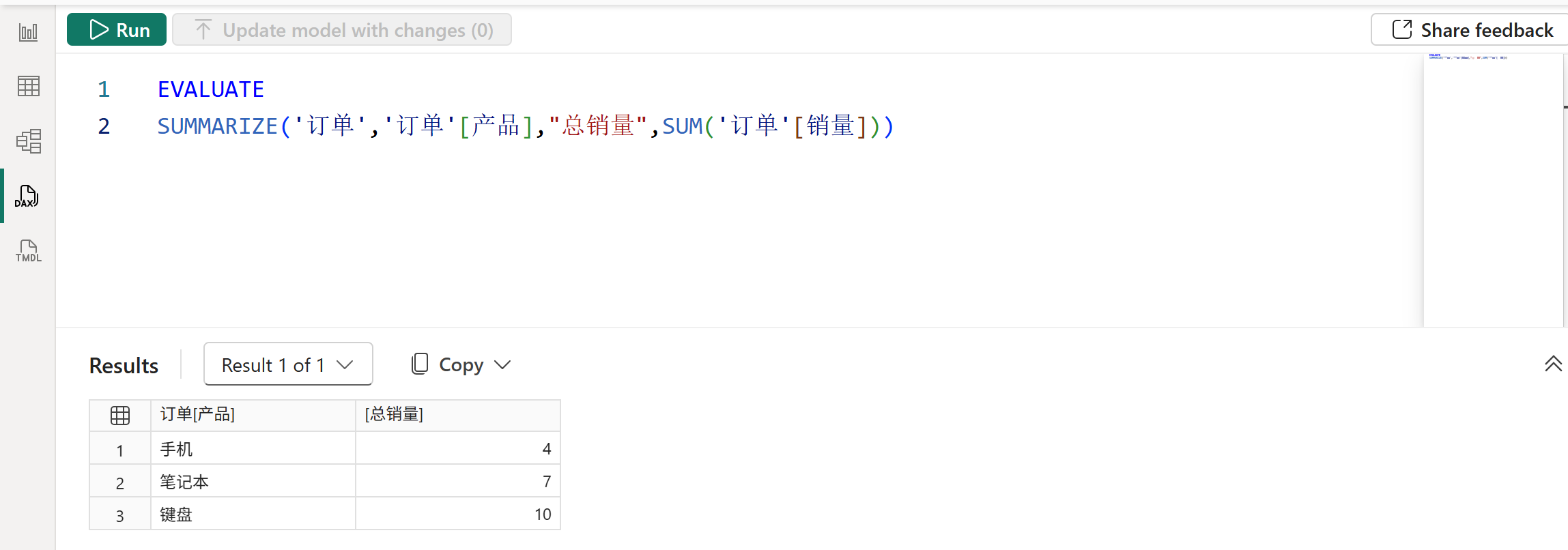
以上图的查询为例,其派生列的计值环境如下图所示:
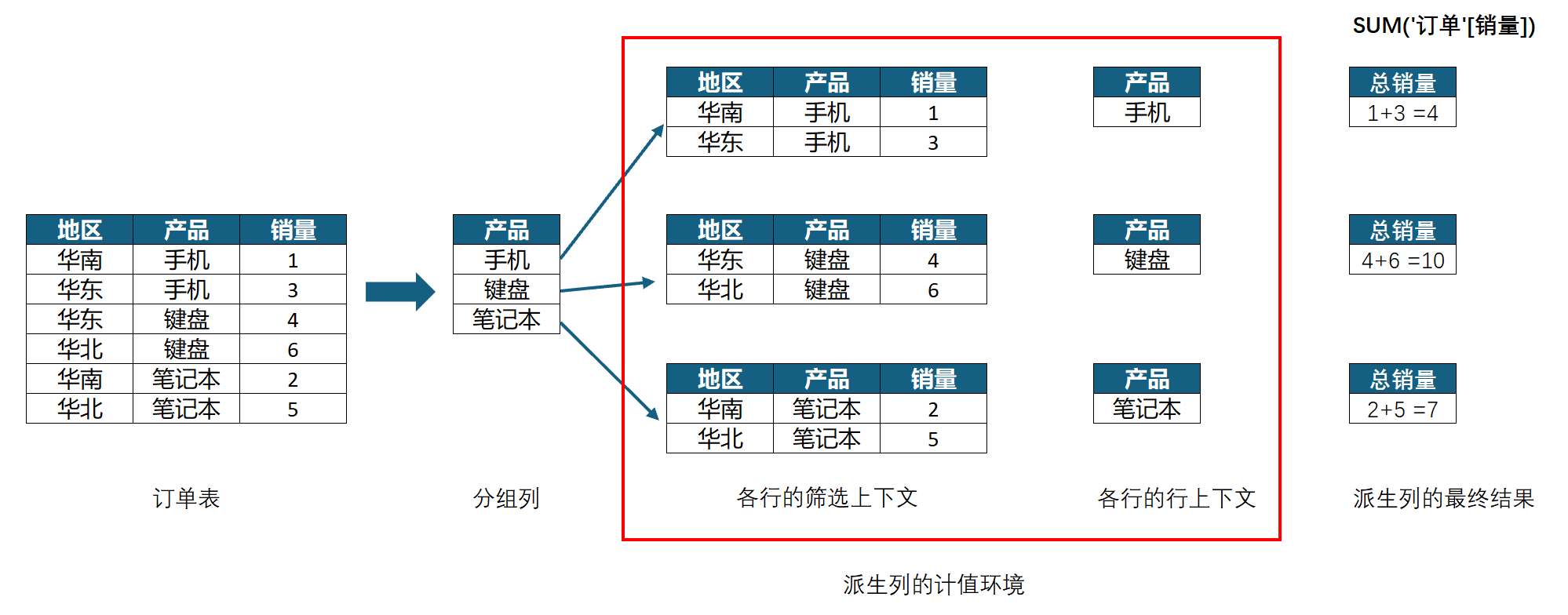
由于派生列的计值环境同时存在行上下文与筛选上下文,因此可以直接使用SUM函数来汇总销量,而不需要使用CALCULATE函数来进行行上下文转换。
此外,也可以直接使用分组列的行上下文,如下图所示:
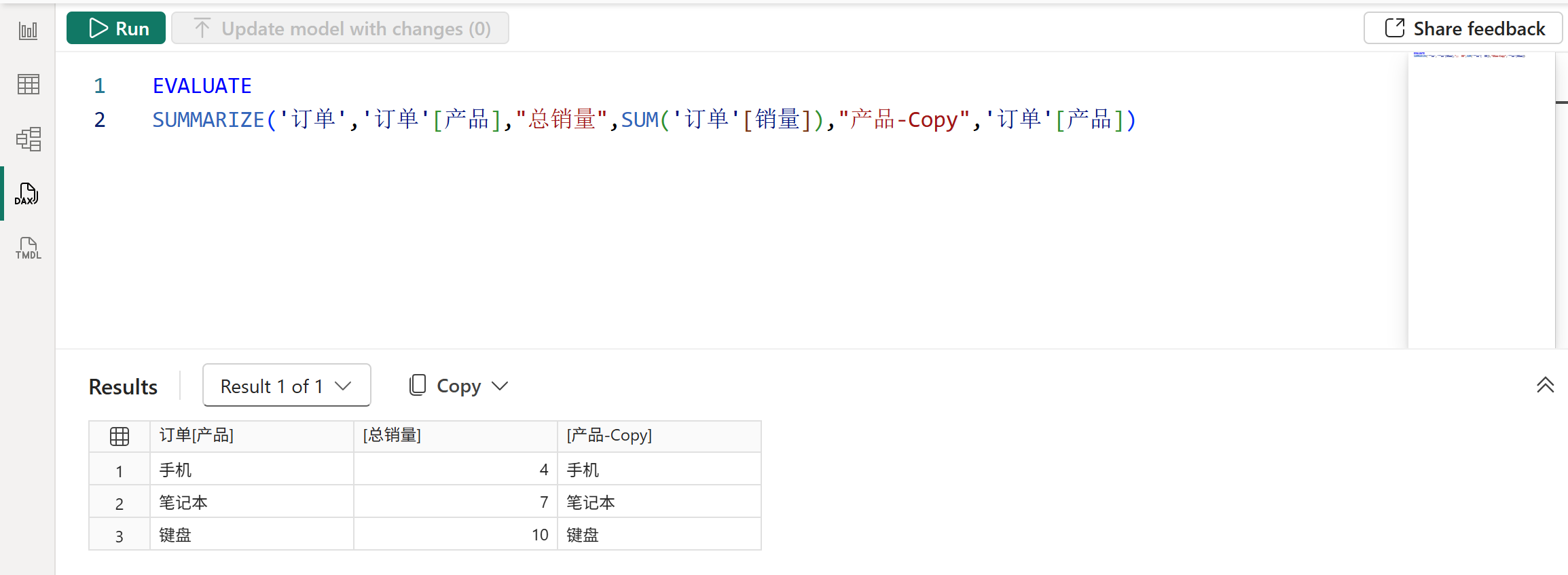
需要注意,由于本案例中只有单个订单表,所以订单表的扩展表等于它自身。如果是在其他模型中,当SUMMARIZE函数的第一参数存在扩展表时,其提供给派生列的筛选上下文的固化筛选器也是包含扩展表上的字段的。
3、由于派生列的计值环境同时存在行上下文与筛选上下文,那么如果派生列中使用了CALCULATE等函数,即发生了行上下文转换,那么筛选上下文其实还是一样的。因为筛选上下文是由第一参数的表在当前分组区间内的值形成的固化筛选器,而这与分组列的行上下文的值是一样的,所以行上下文转换后得到的筛选器去覆盖筛选上下文的固化筛选器,最终得到的筛选器组合仍然是一致的。
但如果进行了行上下文转换,那么就不能再引用行上下文了,如下图所示:
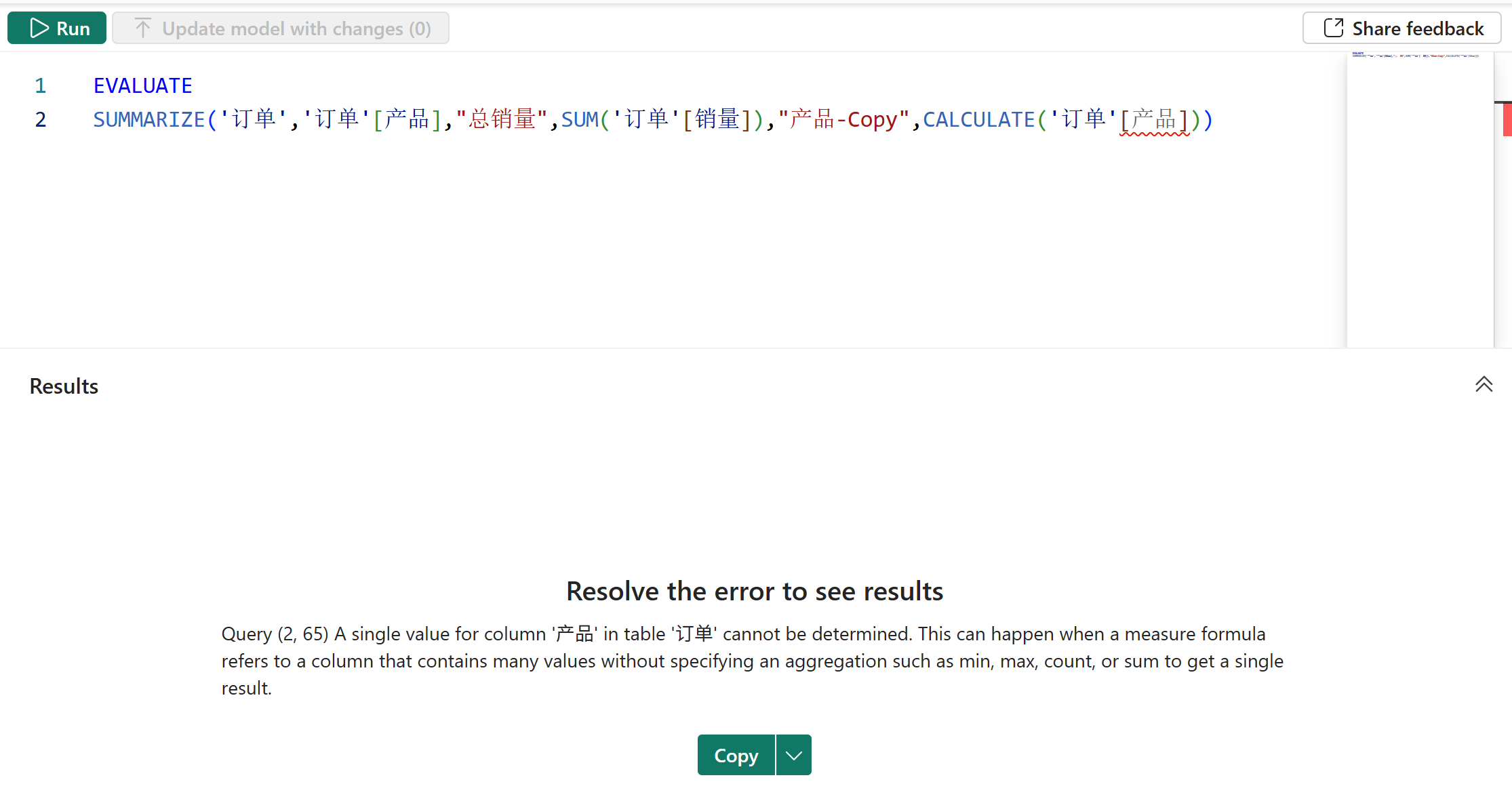
4、如果SUMMARIZE函数第一参数的表包含无数据沿袭的列,那么在派生列的筛选上下文中,这些无数据沿袭的列可以被忽略,因为无数据沿袭的字段无法筛选模型。
首先,地区和产品这两个字段都存在数据沿袭时的结果如下图所示:
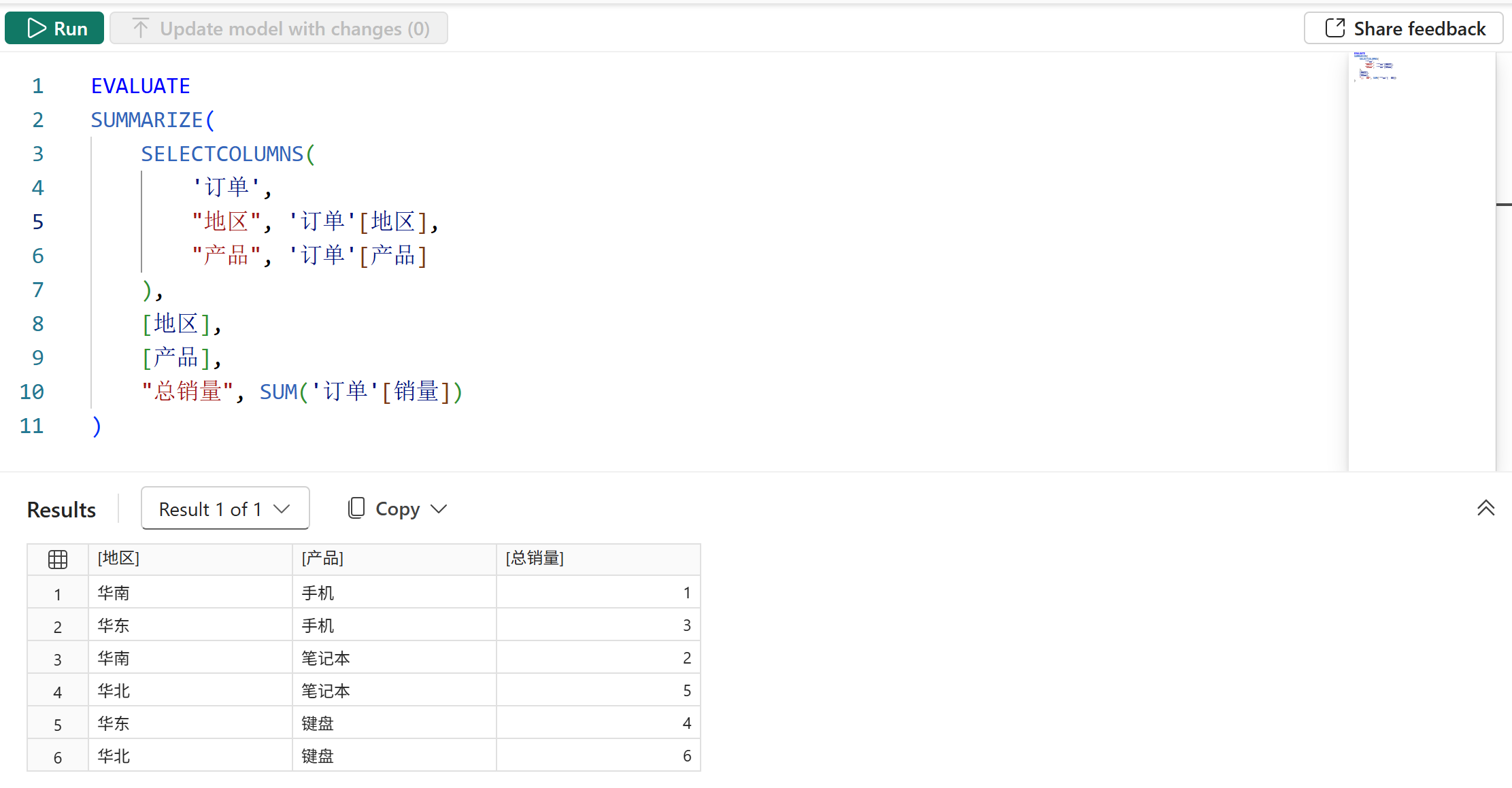
然后,去掉地区字段的数据沿袭后,结果如下图所示:
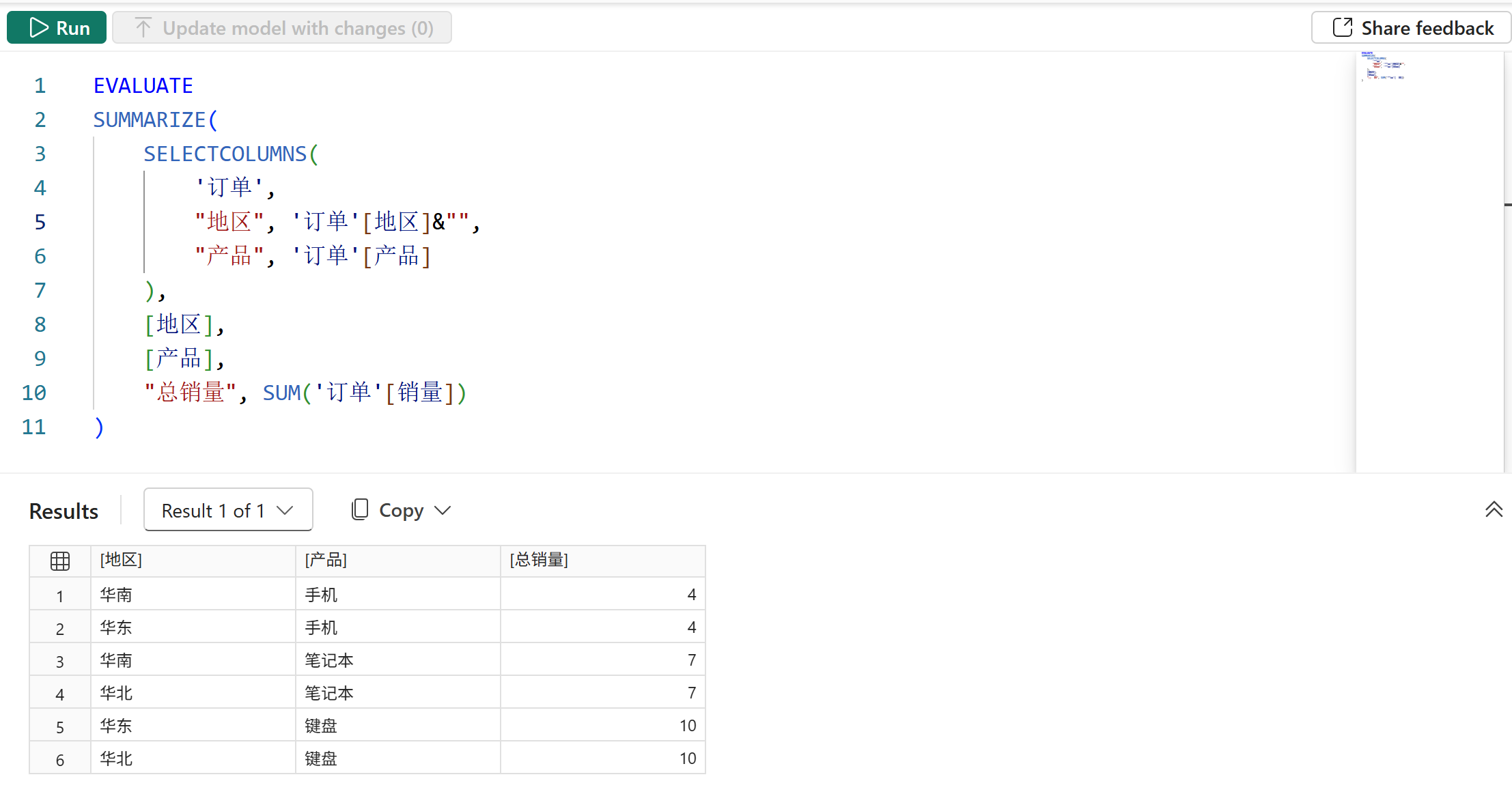
由于地区字段无数据沿袭,所以派生列的筛选上下文中可以忽略地区字段的筛选器,最终只有产品字段的筛选器在起作用。
SUMMARIZE函数的最佳实践
由于SUMMARIZE函数的派生列参数的计值环境较复杂,容易出错,所以一般不推荐使用SUMMARIZE函数的派生列参数,推荐只用SUMMARIZE函数来做分组。
如果需要在SUMMARIZE函数中添加派生列,那么可以采用与ADDCOLUMNS函数结合的方法,具体如下:
EVALUATE
ADDCOLUMNS(
SUMMARIZE('订单','订单'[产品]),
"总销量",CALCULATE(SUM('订单'[销量]))
)通过ADDCOLUMNS函数来添加派生列,计值环境会更简单一点,而且性能相对较好,所以这是比较推荐的一个最佳实践做法。
总结
SUMMARIZE函数在功能强大的同时却隐藏了很多的复杂性,特别是派生列参数,因此在使用时需要重点注意。

















