
GROUPBY函数与SUMMARIZE函数非常类似,都是用来做分组聚合的函数,但GROUPBY函数可能更符合平时所理解的分组操作。
因为GROUPBY函数的派生列参数中不提供任何计值上下文,它使用CURRENTGROUP函数来指代被分组的表在当前分组区间内的行,然后可以使用其他聚合函数对其进行聚合,这与PowerQuery中的分组操作基本一致,所以GROUPBY函数可能更符合平时所理解的分组操作。
语法和作用
语法:
GROUPBY (<table>, <groupBy_columnName>[, <groupBy_columnName>]…[, <name>, <expression>]…)作用:对第一参数的表按指定的分组列进行分组,返回分组列的不重复组合形成的表,并可以往该表中添加派生列。
参数说明:
1、table,要进行分组的表,任意返回表的表达式
2、groupBy_columnName,要进行分组的列,必须来自第一参数的表或其扩展表
3、name,添加的派生列的列名
4、expression,添加的派生列的表达式,必须是对CURRENTGROUP函数返回的当前分组区间的表的聚合,并且不能嵌套
注意事项:
1、分组列必须来自第一参数的表,否则会报错。
2、若第一参数的表存在扩展表,那么第二参数的分组列可以是其扩展表上的任意列。
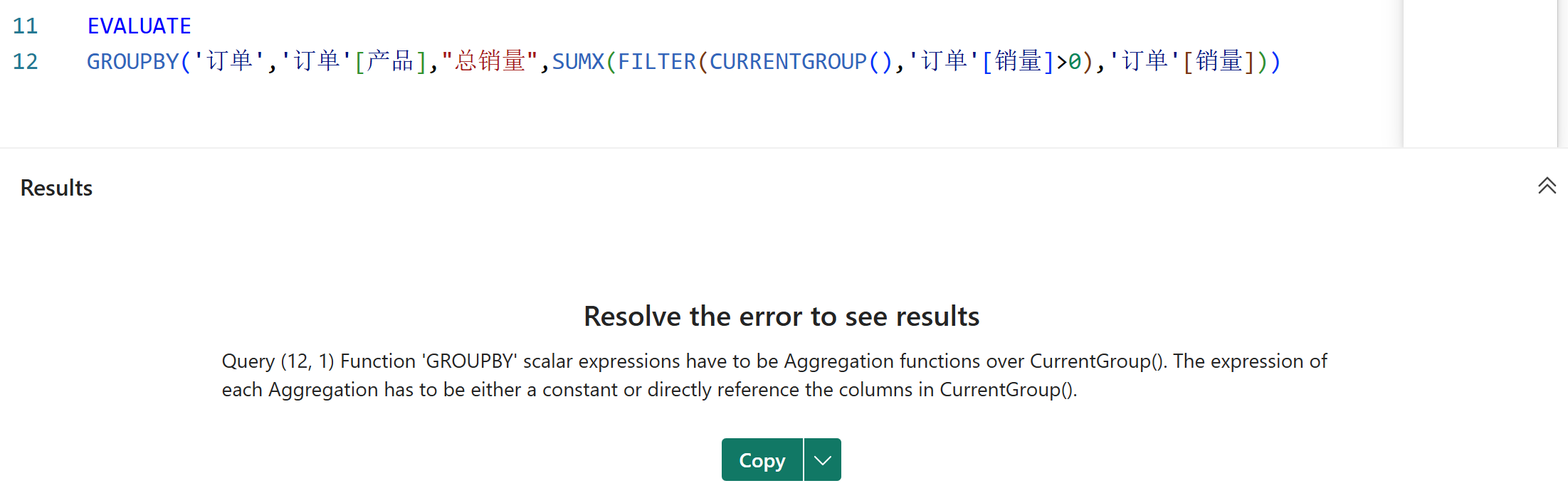
3、派生列的表达式中,CURRENTGROUP函数必须要直接作为聚合函数的第一参数,其支持的聚合函数有:AVERAGEX、COUNTAX、COUNTX、GEOMEANX、MAXX、MINX、PRODUCTX、STDEVX.S、STDEVX.P、SUMX、VARX.S、VARX.P
辅助理解的例子
首先,用到的数据源只有一张表,如下图所示:

1、不添加派生列,使用GROUPBY函数返回分组列的不重复组合形成的表,如下图所示:
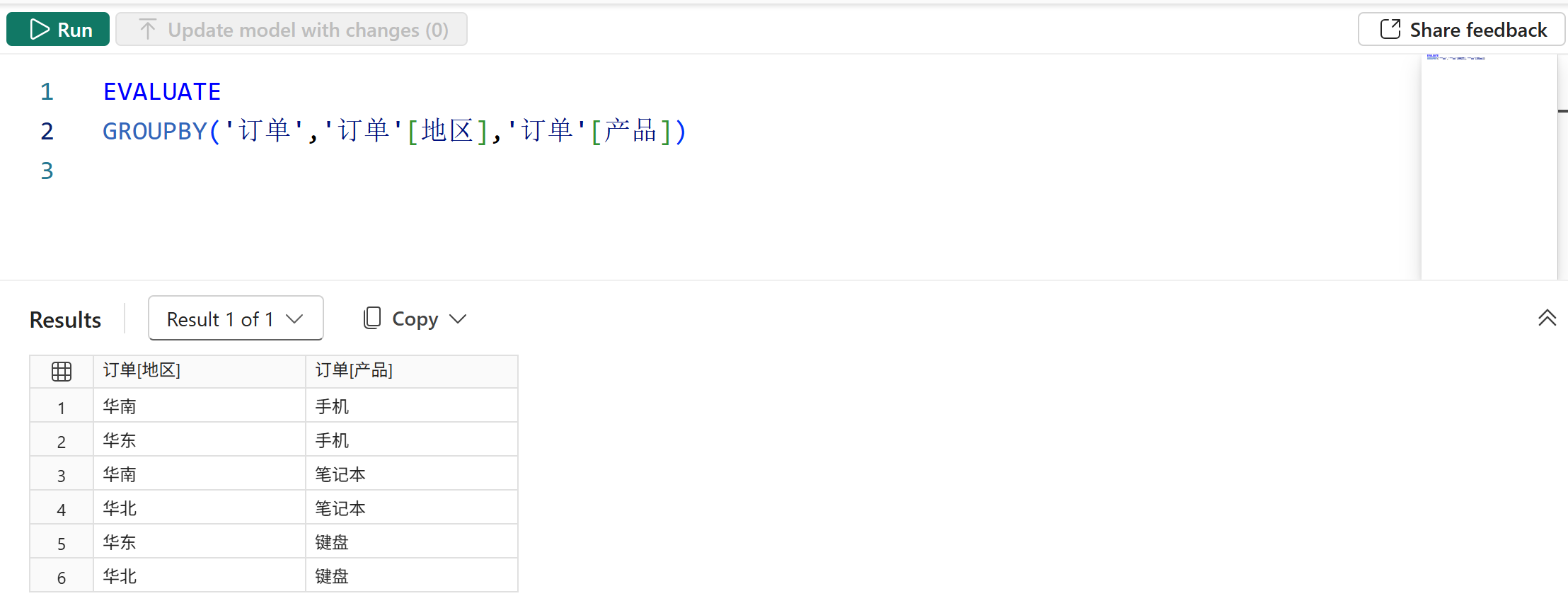
由于没有添加派生列,此时GROUPBY函数的行为就是从第一参数的表中提取分组列参数所指定的字段,然后进行去重。为方便理解,如果用其他函数来表达的话,其行为等价于以下表达式:
GROUPBY('订单','订单'[地区],'订单'[产品])
等价于:
DISTINCT(SELECTCOLUMNS('订单','订单'[地区],'订单'[产品]))2、GROUPBY函数的派生列参数中不提供任何计值上下文,它使用CURRENTGROUP函数来指代被分组的表在当前分组区间内的行,然后可以使用其支持的聚合函数对其进行迭代聚合,如下图所示:
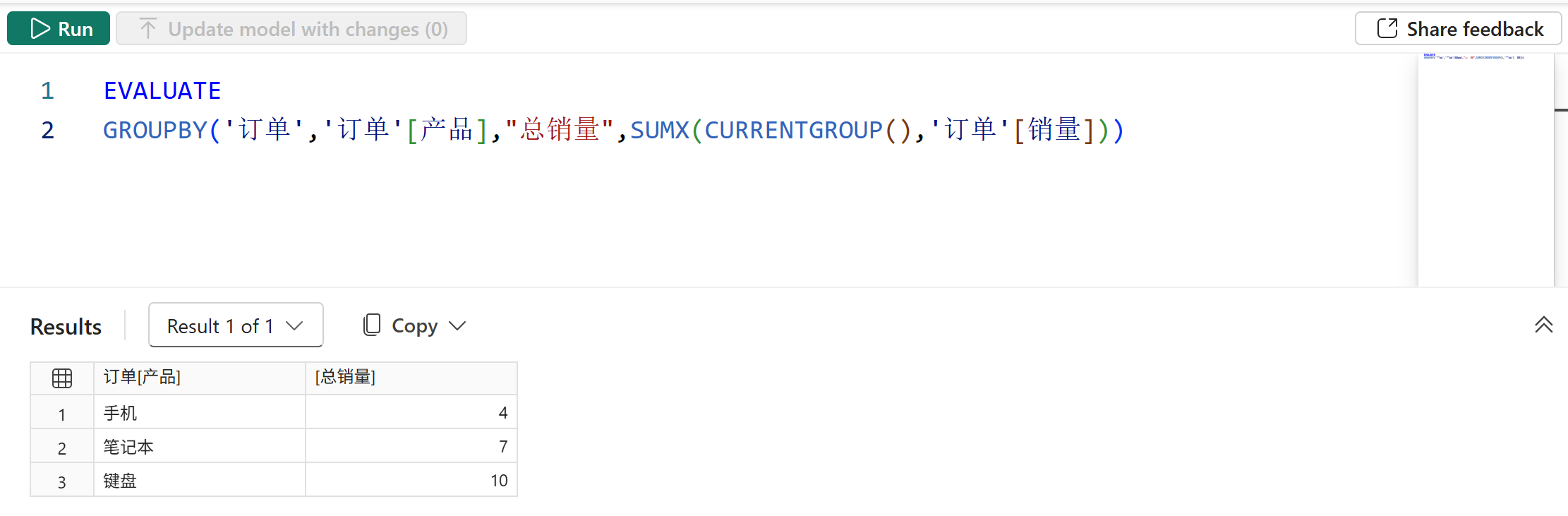
其计值流程如下:
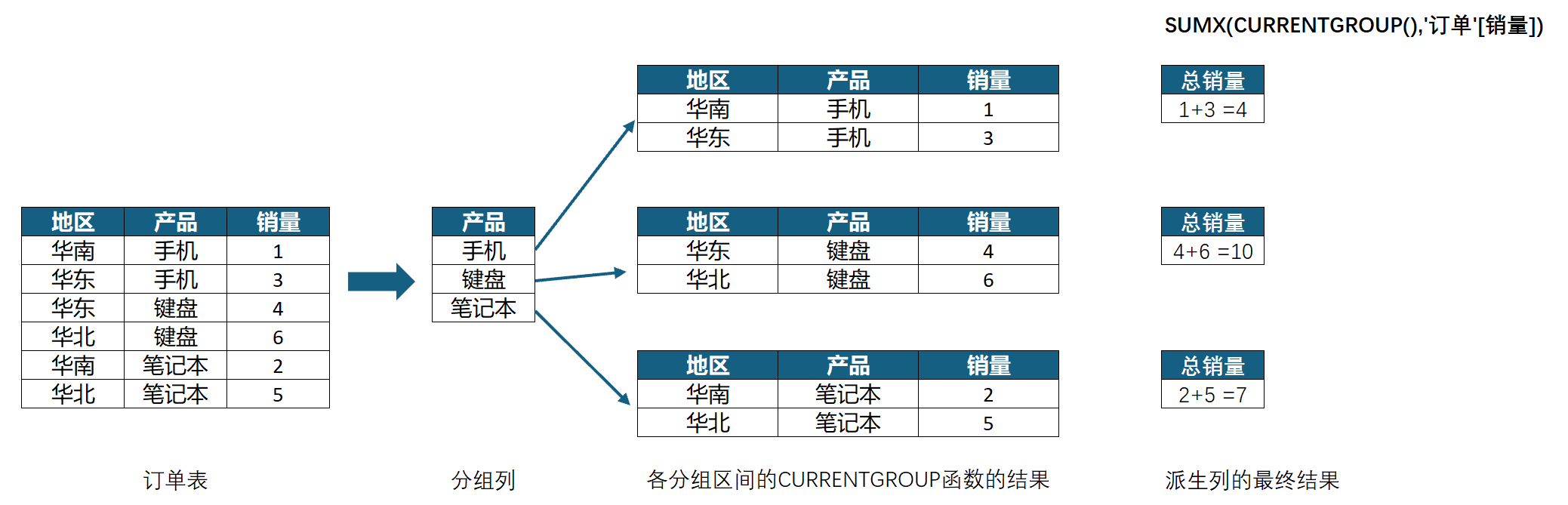
3、GROUPBY函数的派生列参数中,CURRENTGROUP函数必须要直接作为聚合函数的第一参数,否则会报错,如下图所示:
4、不支持对CURRENTGROUP函数返回的表进行行上下文转换,如下图所示:
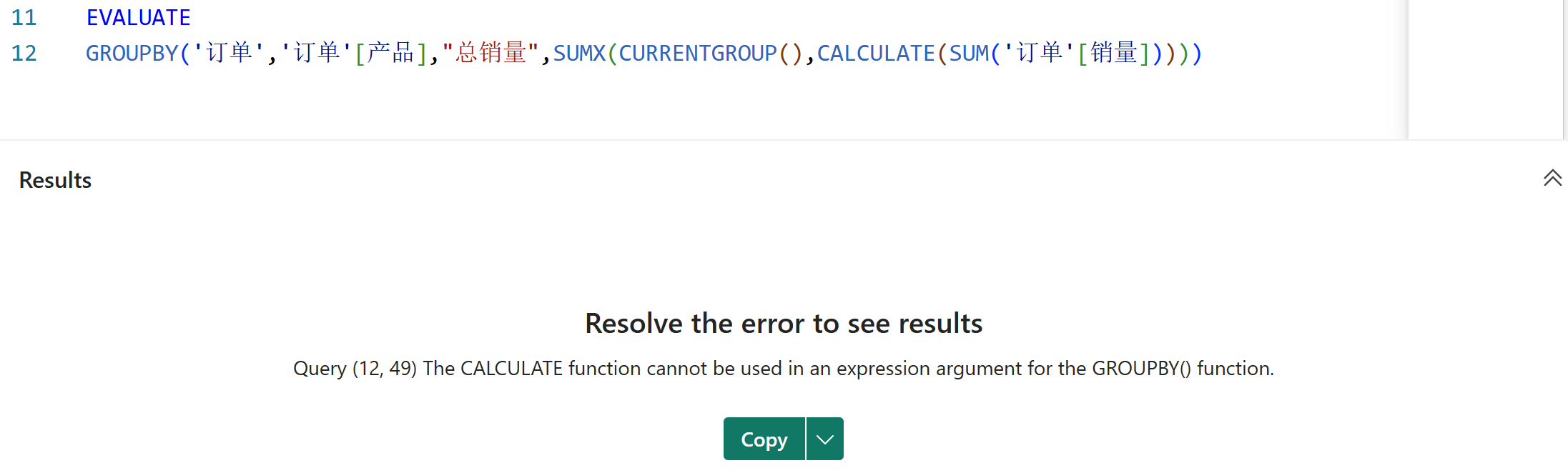
5、由于GROUPBY函数可以使用CURRENTGROUP函数来获取当前分组区间的数据,所以特别适合要对无数据沿袭的派生列进行聚合的场景,而这是SUMMARIZE函数所做不到的,比如以下案例:
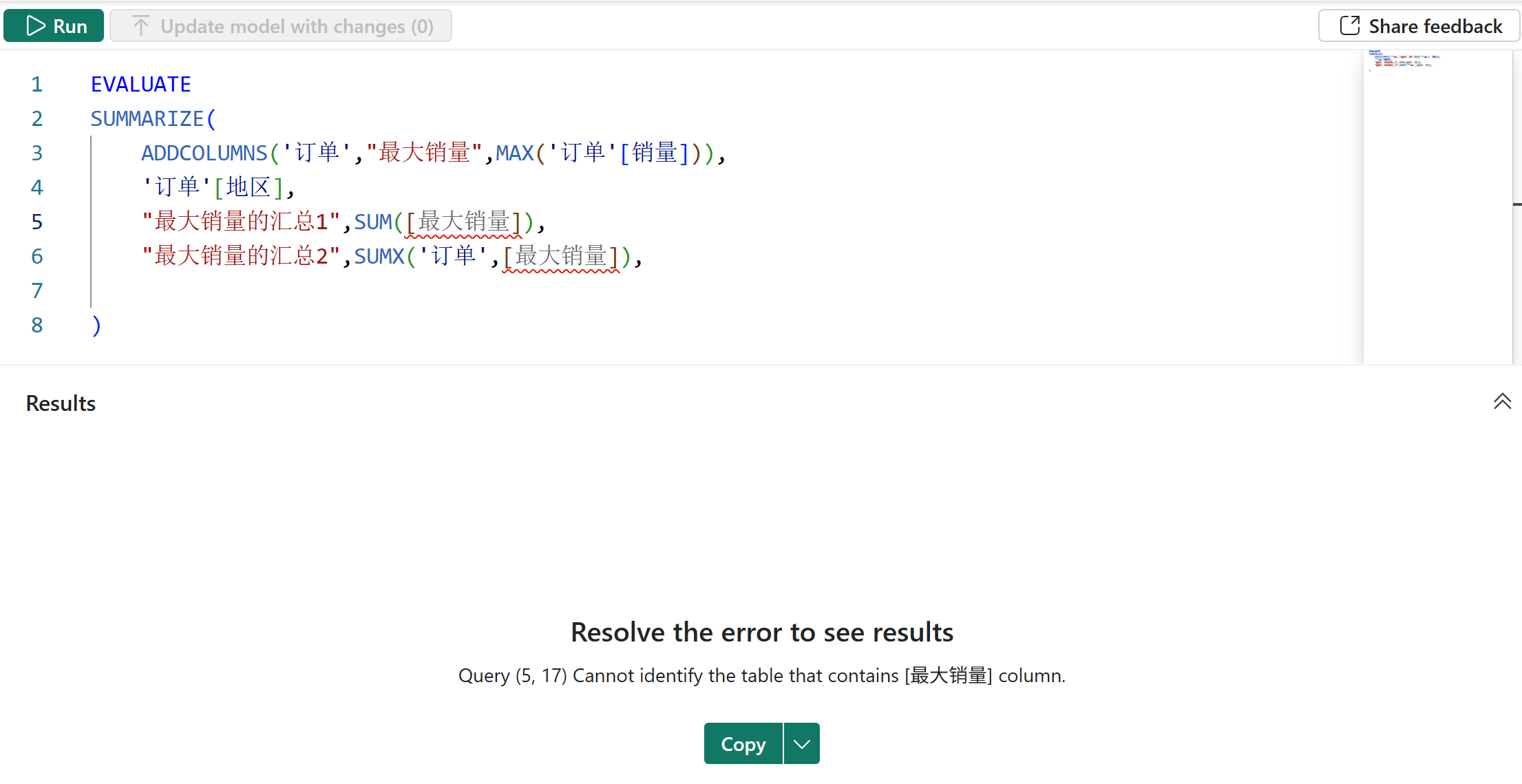
由于最大销量这个派生列在模型中不存在,所以SUMMARIZE函数的派生列参数中是引用不到它的,因此也就无法进行下一步的操作。而这时改用GROUPBY函数就可以很容易的实现这个目的,如下图所示:
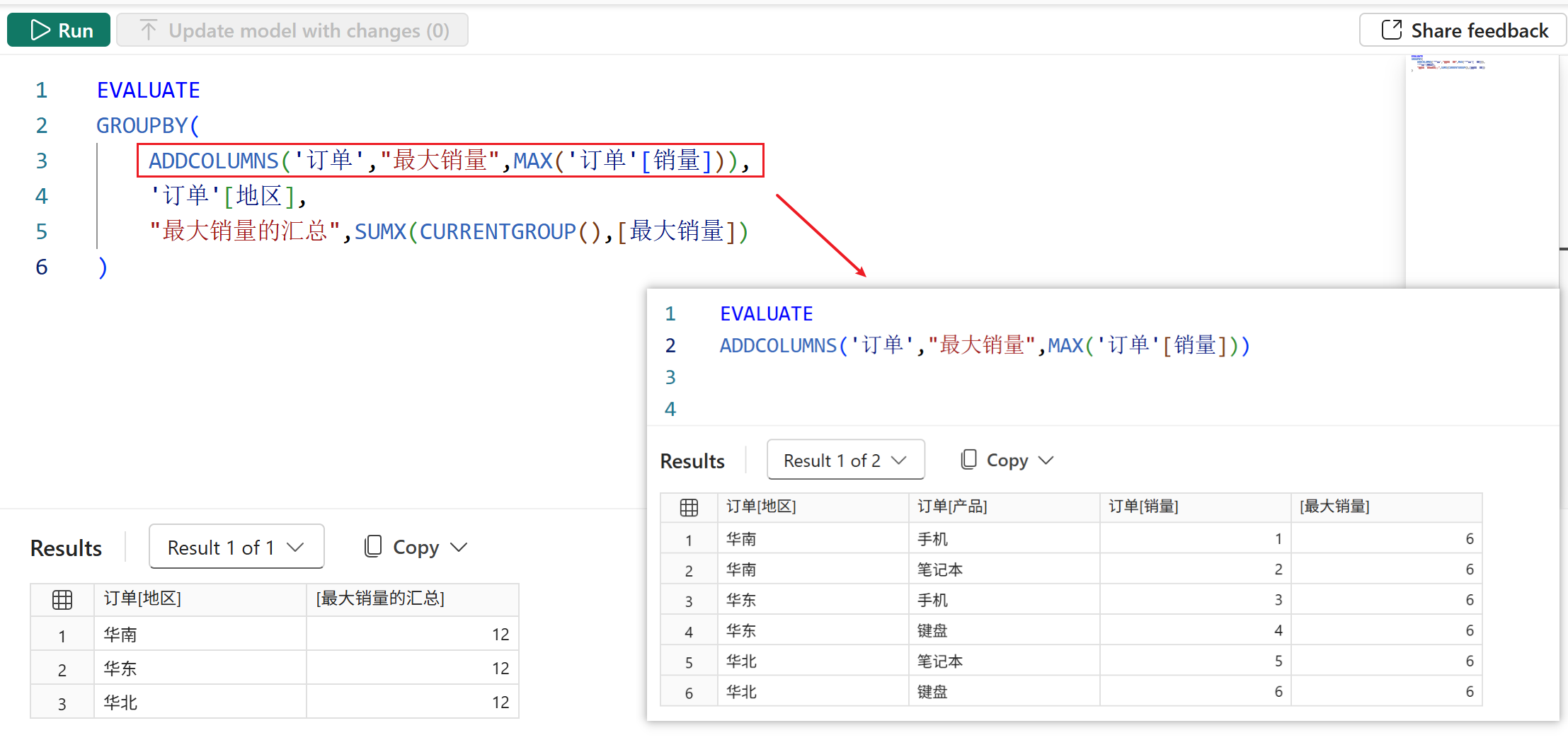
总结
GROUPBY函数和SUMMARIZE函数都能进行分组聚合,但GROUPBY函数的行为更符合平时所理解的分组操作,因此特别适合那些对派生列指标进行聚合的场景,而这是SUMMARIZE函数所做不到的。

















