
SELECTCOLUMNS函数与ADDCOLUMNS函数非常类似,SELECTCOLUMNS函数也是迭代表的每一行并计算所给的表达式,最后给表添加新列,但它最终只返回新添加的派生列,而不会返回原有列。
语法和作用
语法:
SELECTCOLUMNS(table_expression, name, scalar_expression [, name, scalar_expression]…)作用:从空表开始添加派生列,派生列将在第一参数的表提供的行上下文和外部计值上下文中进行计算,最终返回只包含新添加的派生列的新表。
注意:添加的计算列若直接引用列,且引用的列与第一参数的表的列名一致,则会继承该列的数据沿袭。此外,返回的表不包含第一参数所指定表的扩展表,哪怕引用第一参数的表的所有列。
辅助理解的例子
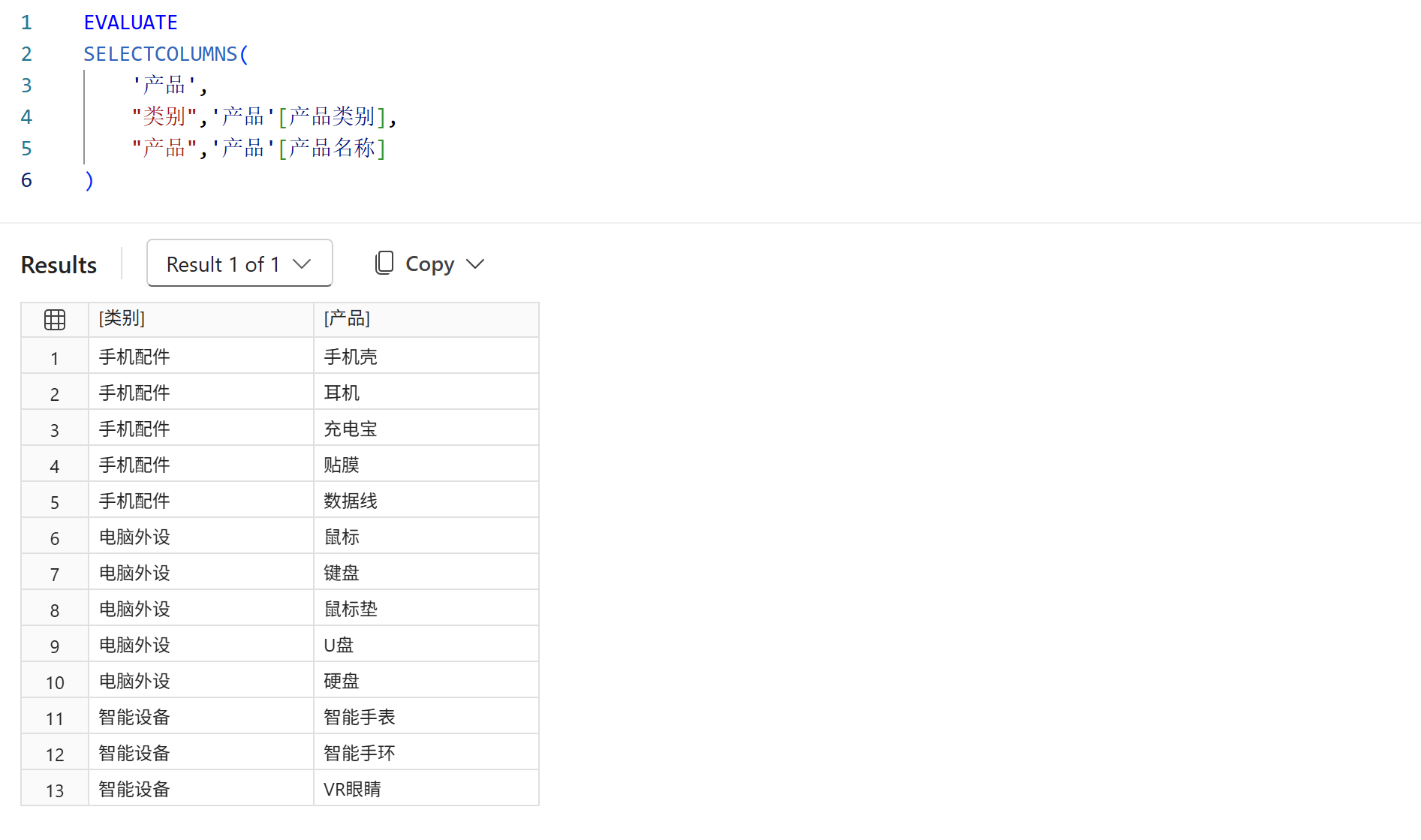
由于派生列的计值环境包括第一参数的表的行上下文,所以可以使用SELECTCOLUMNS函数提取表中所需的部分字段,并可以对列名进行重命名,如下图所示:
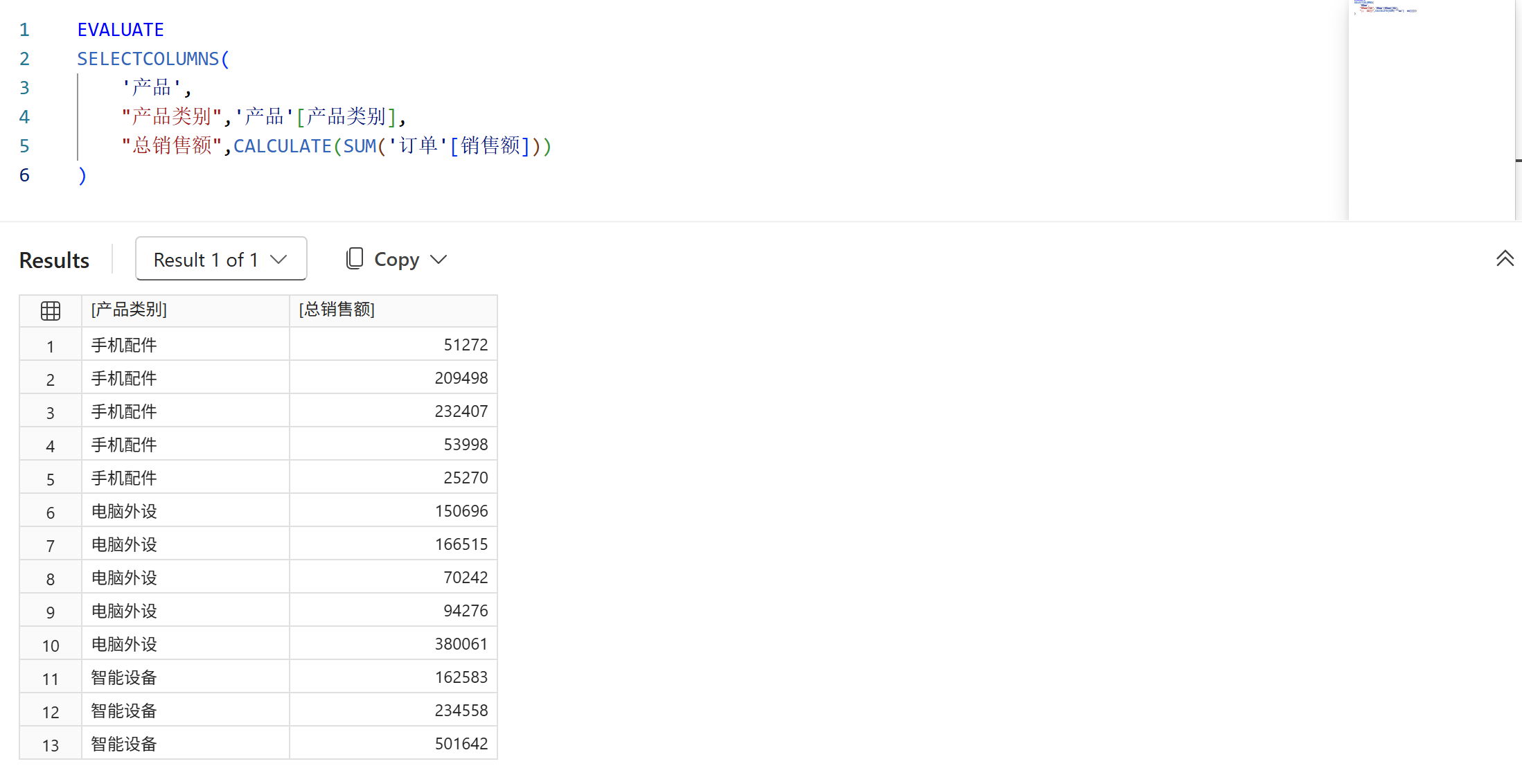
除了提取第一参数的表的原有列外,还可以添加使用表达式计算出来的派生列。如下图所示,从产品表中提取产品类别字段,并添加总销售额字段。
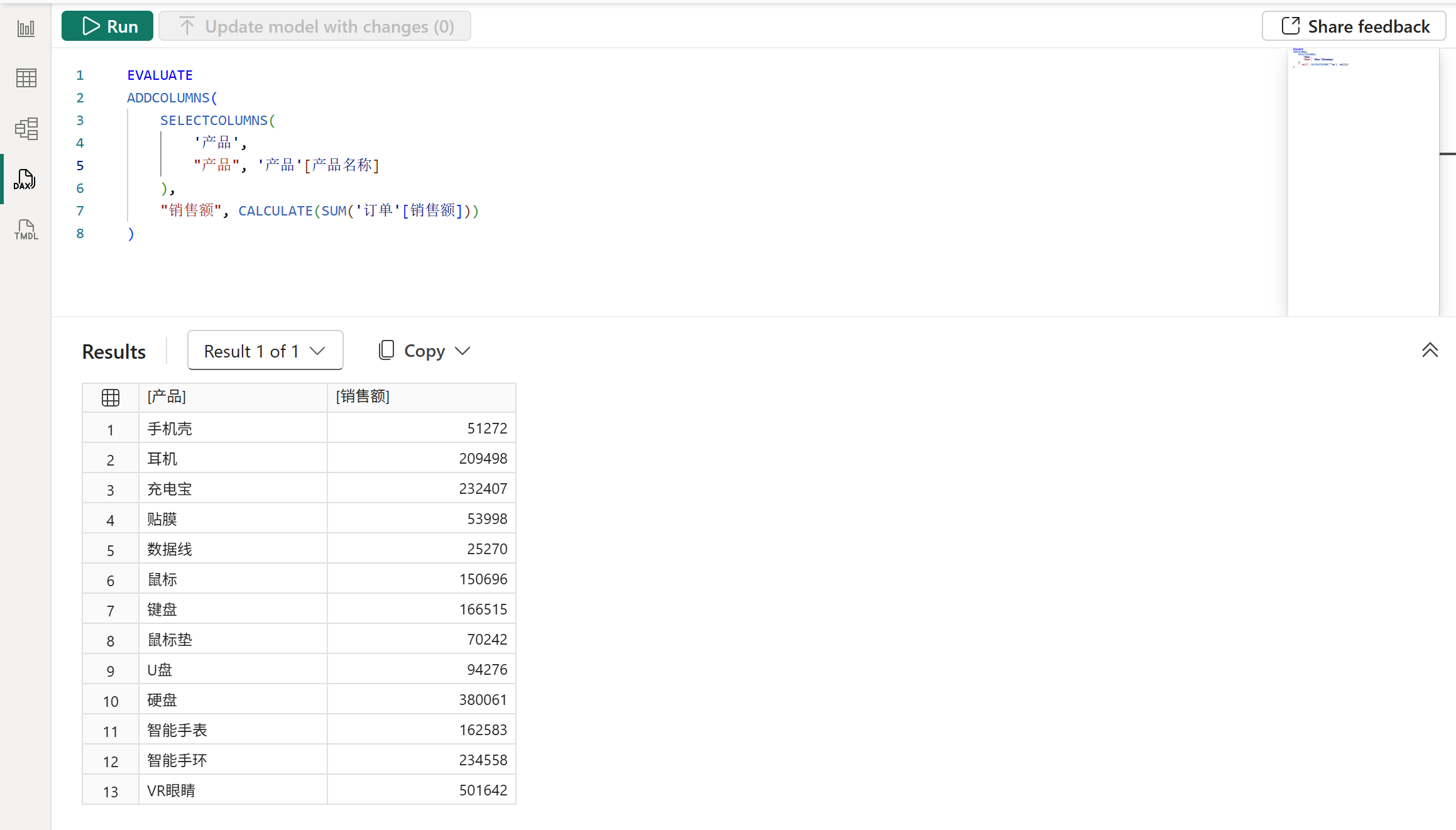
在SELECTCOLUMNS函数中,如果是直接引用列的话,那么是具有数据沿袭的,体现为行上下文转换后得到的筛选器能够正常筛选订单表,从而得到各个产品的销售额,如下图所示:
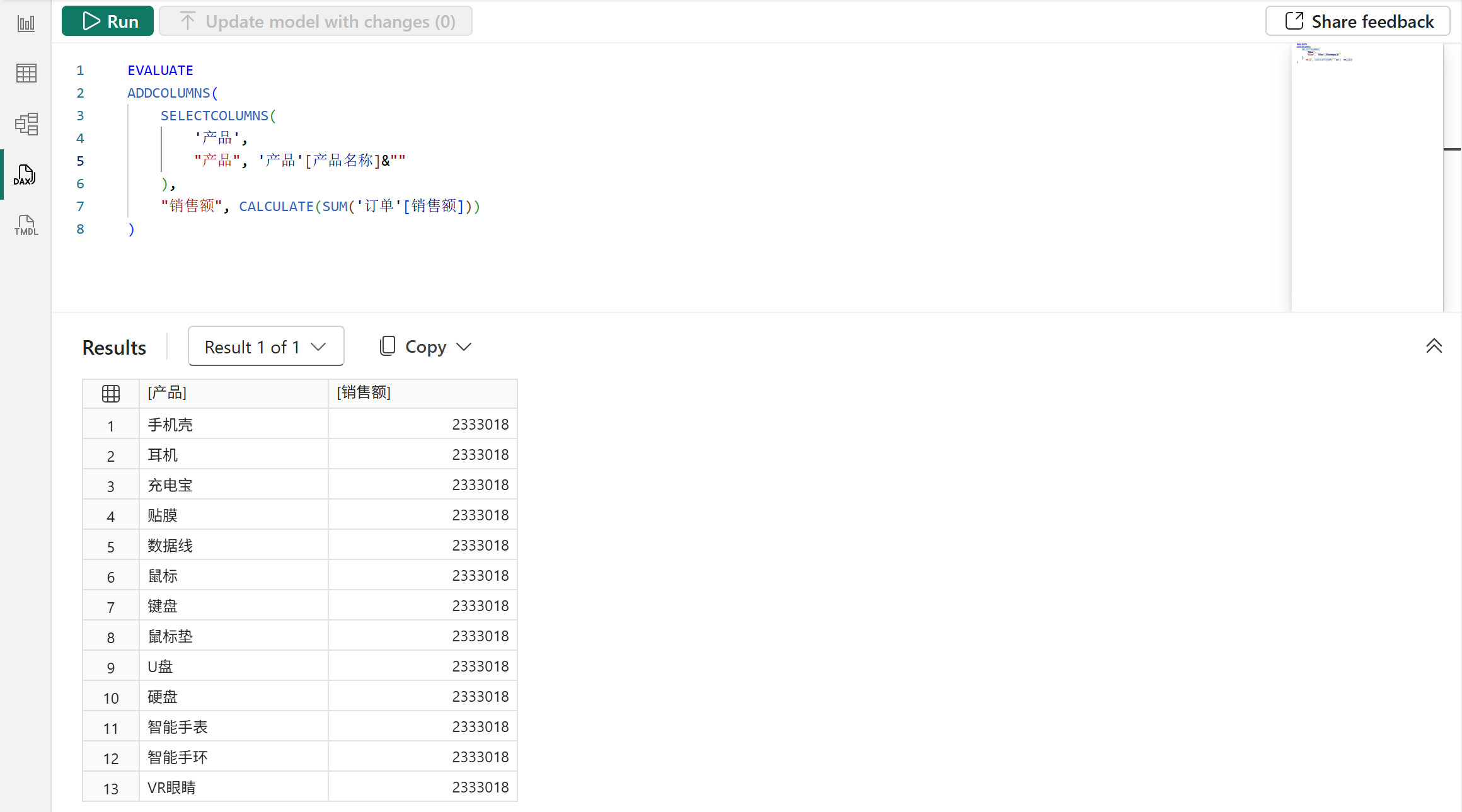
但如果在SELECTCOLUMNS函数中额外使用了其他函数或运算符,比如给产品名称的列引用拼接了一个空字符串,那么虽然值看起来是一样的,但实际上已经不具有数据沿袭了,最终导致行上下文转换后的筛选器无法筛选模型中的数据,最终返回了总销售额,如下图所示:
此外,如果是直接引用列,并且不需要更改列名的情况下,那么可以把列名参数给省略掉,如下图所示:

最后,SELECTCOLUMNS函数返回的表是不包含扩展表的,即使在后面的派生列中直接引用了第一参数的表的所有列。如下图所示:
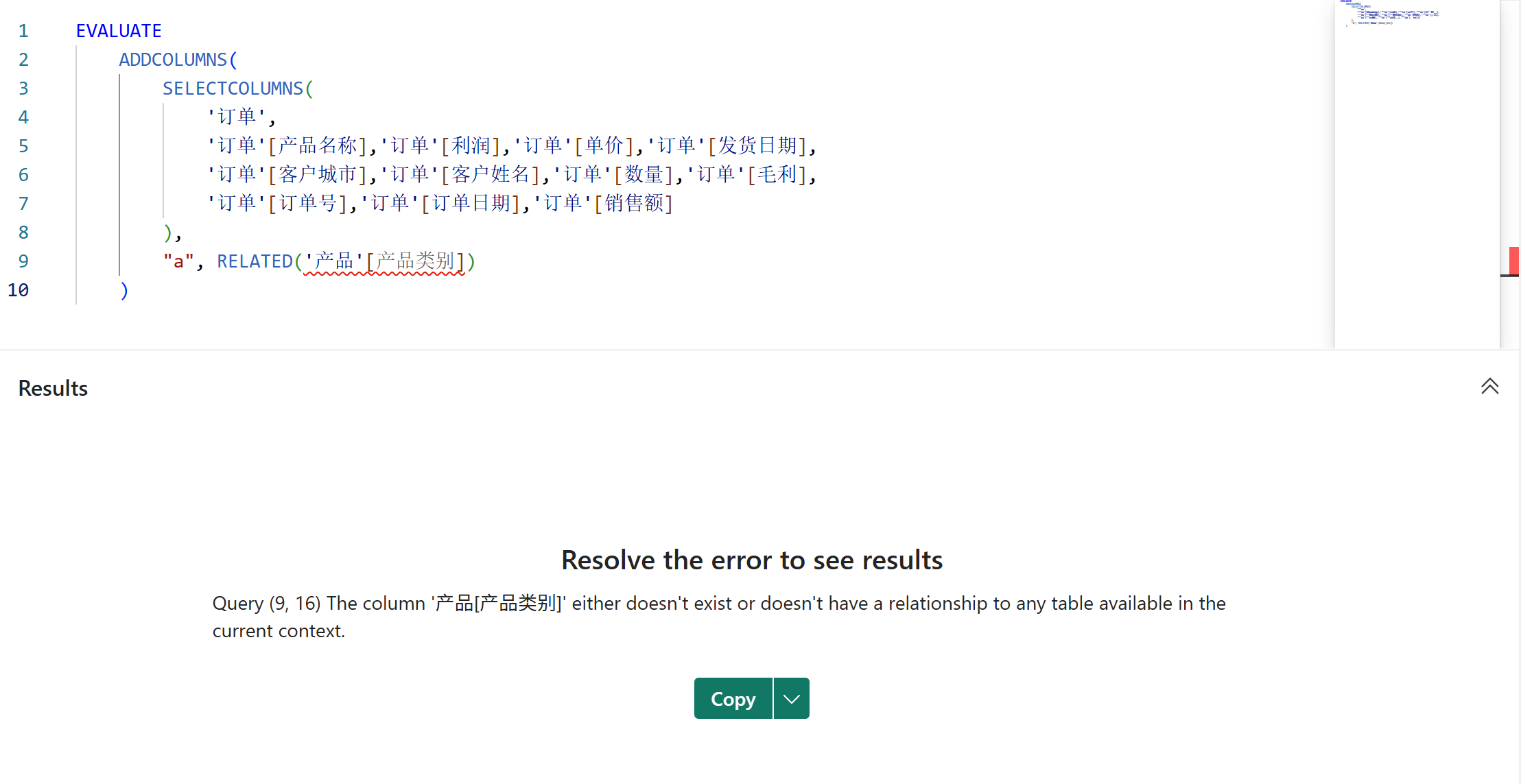
由于不存在扩展表,所以无法使用RELATED等依赖扩展表的函数。
总结
SELECTCOLUMNS函数可以自由的提取原有列并添加派生列,也是一个很常用的表函数,建议掌握。

















