
前言
在2022年9月左右的更新中,DAX中新增了窗口函数这一个类别,推出了OFFSET、INDEX、WINDOW等窗口函数,并在后续的更新中又新增了新的RANK、ROWNUMBER这两个窗口函数。
窗口函数的出现简化了DAX中原本较复杂的一些计算,比如当前行与上N行或下N行等位置偏移的相对运算,或从首行到当前行等的滑动窗口运算等等。这些计算在没有窗口函数前也并不是不能算,只是都需要编写较复杂的代码来实现。
因此,窗口函数是必须要掌握的一类函数,它可以有效简化一些复杂运算,并可以用在新出的视觉计算功能中,应用场景与作用都非常广泛。
本篇文章将介绍窗口函数的所有细节与限制,以及计值流程、应用语义等关键知识点,带你了解它的所有秘密!
窗口函数的语法
由于各个窗口函数的语法和参数都比较类似,并且核心计值流程都是一样的,只是最后步骤的行为略有区别,因此可以把窗口函数的语法抽象成如下:
FUNCTION( [<rowSelect>][, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )参数说明:
1、rowSelect,可以是返回任意整数的表达式,计值环境为窗口函数的外部计值环境。该参数是OFFSET、INDEX、WINDOW这三个函数的必选参数,其他窗口函数则没有这个参数。该参数可以控制如何在当前分区中根据行的绝对位置或基于当前行的相对位置来偏移或滑动窗口来选择具体要返回的行。
2、relation,任意返回表的表达式,计值环境为窗口函数的外部计值环境。该参数是所有窗口函数的必选参数,是窗口函数进行行偏移或窗口滑动等操作的基础。虽然该参数从语法来看是可以省略的,但省略时DAX引擎会根据另外的参数来生成这个参数,所以其实还是必选的。另外,该参数虽然可以是任意返回表的表达式,但还是要满足一定要求与限制的,是有条件的任意,具体限制请参考后文。
3、orderBy,使用ORDEREBY函数的一个语法子句,该参数是所有窗口函数的必选参数,用于对relation参数返回的表进行排序。同样的,该参数从语法来看也是可以省略的,但省略时DAX引擎会自动添加一个对relation参数返回的表中的所有具有数据沿袭的列进行排序的orderBy参数,并且引擎添加的排序顺序可能并无规则,因此为了保证排序的正确,这个参数其实也是必选的。
ORDERBY函数只能用于窗口函数的orderby参数中,其语法结构如下:
ORDERBY( <OrderExpression> [,<Order> [,<OrderExpression> [,<Order>]]...] )OrderExpression,任意返回标量值的表达式,其结果将被用于排序,计值环境为窗口函数的外部计值环境,以及窗口函数中的relation参数的表提供的行上下文。注意:该参数支持度量值等各种返回标量值的表达式,需要注意由行上下文转换所带来的计值环境变化。Order,一个枚举值,用于控制升序或降序,值为1或ASC时是升序,值为0或DESC时是降序,省略该参数时默认升序。- 以上两个参数都是可重复的,因此可以按多个条件来排序。当存在多个排序条件时,会先用第一个排序条件进行排序,然后再对其中重复行部分应用第二个排序条件进行排序,以此类推。
4、blanks,一个枚举值,用于定义排序时如何处理空值,该参数是所有窗口函数都有的一个可选参数,一般省略保持默认即可。可选的枚举值如下:
DEFAULT,对数值进行排序时,空值将排在零和负数之间;对字符串进行排序时, 空值将排在包括空字符串的所有字符串之前。FIRST,无论升序或降序,空值始终排在开头。LAST,无论升序或降序,空值始终排在末尾。
5、partitionBy,使用PARTITIONBY函数的一个语法子句,该参数是所有窗口函数都有的一个可选参数,可以用来对relation参数的表按指定列进行分区。当省略该参数时,整个relation参数的表会被视为单个分区。
PARTITIONBY函数只能用于窗口函数的partitionBy参数中,其语法结构如下:
PARTITIONBY( [<partitionBy_columnName>[, partitionBy_columnName [, …]]] )其中的partitionBy_columnName参数必须是来自窗口函数的relation参数的表中的有数据沿袭的列,该参数可以重复,即可以按多个列为条件来进行分区。
6、matchBy,使用MATCHBY函数的一个语法子句,该参数是所有窗口函数都有的一个可选参数,可以控制在应用语义中确定当前行时所使用的字段。当省略该参数时,将使用relation参数的表中所有具有数据沿袭的列来确定当前行,具体请参考后文的应用语义部分。
MATCHBY函数只能用于窗口函数的partitionBy参数中,其语法结构如下:
MATCHBY( [<matchBy_columnName>[, matchBy_columnName [, …]]] )其中的matchBy_columnName参数必须是来自窗口函数的relation参数的表中的有数据沿袭的列,该参数可以重复,即可以使用指定的多个字段来确定当前行。另外,matchBy_columnName参数指定的所有列需要能唯一标识每个分区中的每一行,否则会报错,因为matchBy参数隐含的另一种作用就是指定主键。
窗口函数的成员
目前窗口函数的数量有五个,即:OFFSET、INDEX、WINDOW、RANK、ROWNUMBER等函数,他们的语法和参数都比较类似,只要掌握了窗口函数的核心计值流程与应用语义,就可以一次性掌握完所有窗口函数。这有点像之前介绍过的迭代函数,他们的核心计值流程都是一样的,只是最后步骤的行为略有区别。
因此在介绍具体的计值流程与应用语义等关键内容前,先来介绍一下各个窗口函数的语法与作用。
注意:本小节只介绍各个窗口函数的独有参数与大概作用,其他共有参数的介绍请见上文,计值流程等则请参考后文。在本小节中,因为还没有介绍计值流程等内容,如果描述或示例看不懂也是很正常的,只需要对各个函数的行为与作用有个简单了解即可,后面可回过头来重新阅读。
窗口函数的共有参数为:relation、orderBy、blanks、partitionBy、matchBy。
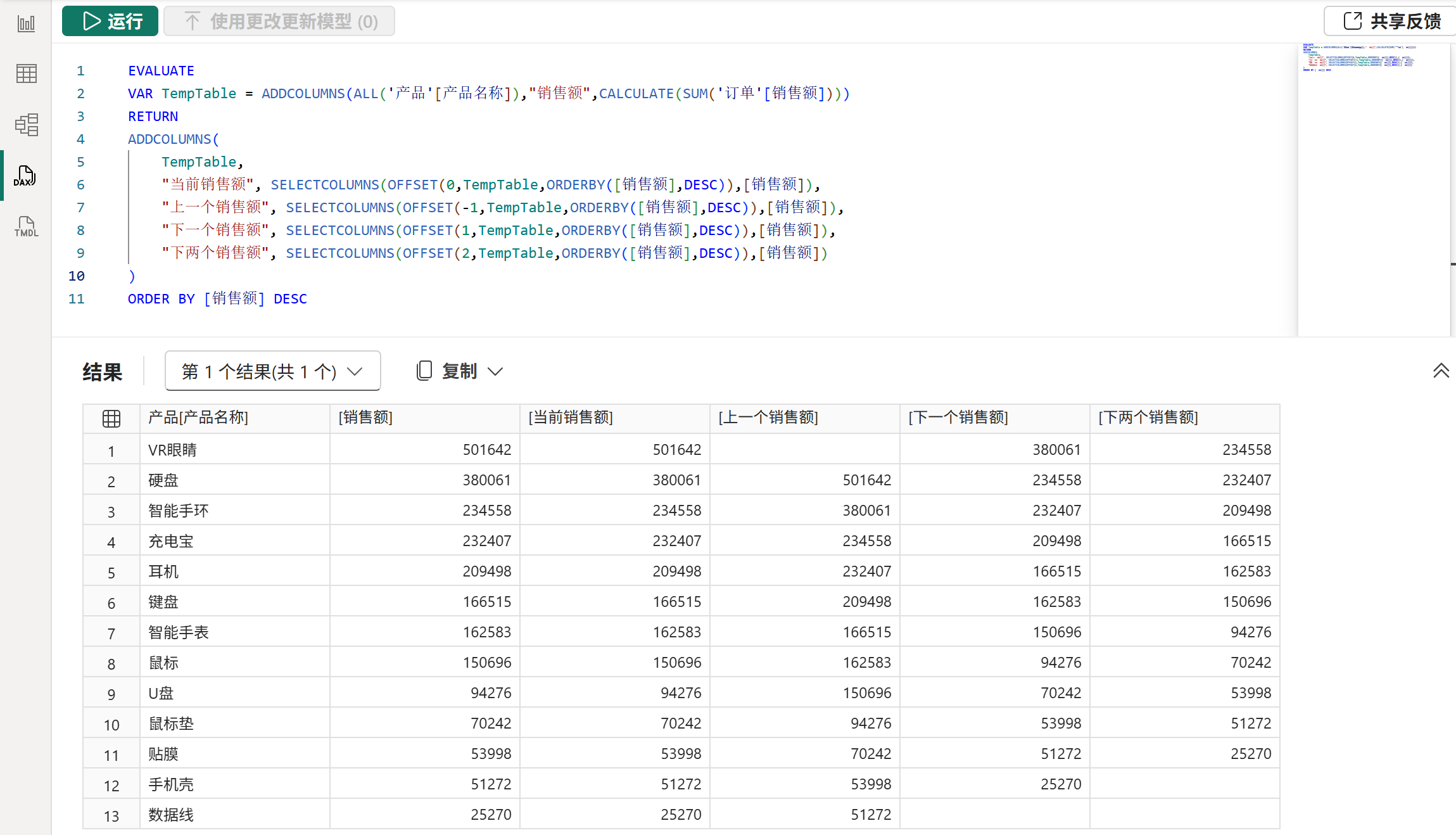
1、OFFSET函数
语法:
OFFSET( <delta>[, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )作用:
在经过partitionBy参数分区和orderby参数排序后的relation参数的表中,在当前分区中基于当前行向上或向下移动delta行,返回移动后所在的行。
delta参数不能省略,它可以是任意整数,0代表不移动,正数代表向下移动,负数代表向上移动。
注意:
1、当delta参数指定的移动行数过大,超出了第一行或最后一行时,将会返回空表。
2、当前行有时候可能并不止一行,当存在多个当前行时,会基于各个当前行进行偏移,最终返回合并且去重后的结果。关于当前行的确定,具体请参考后文的计值流程和应用语义部分。
示例:
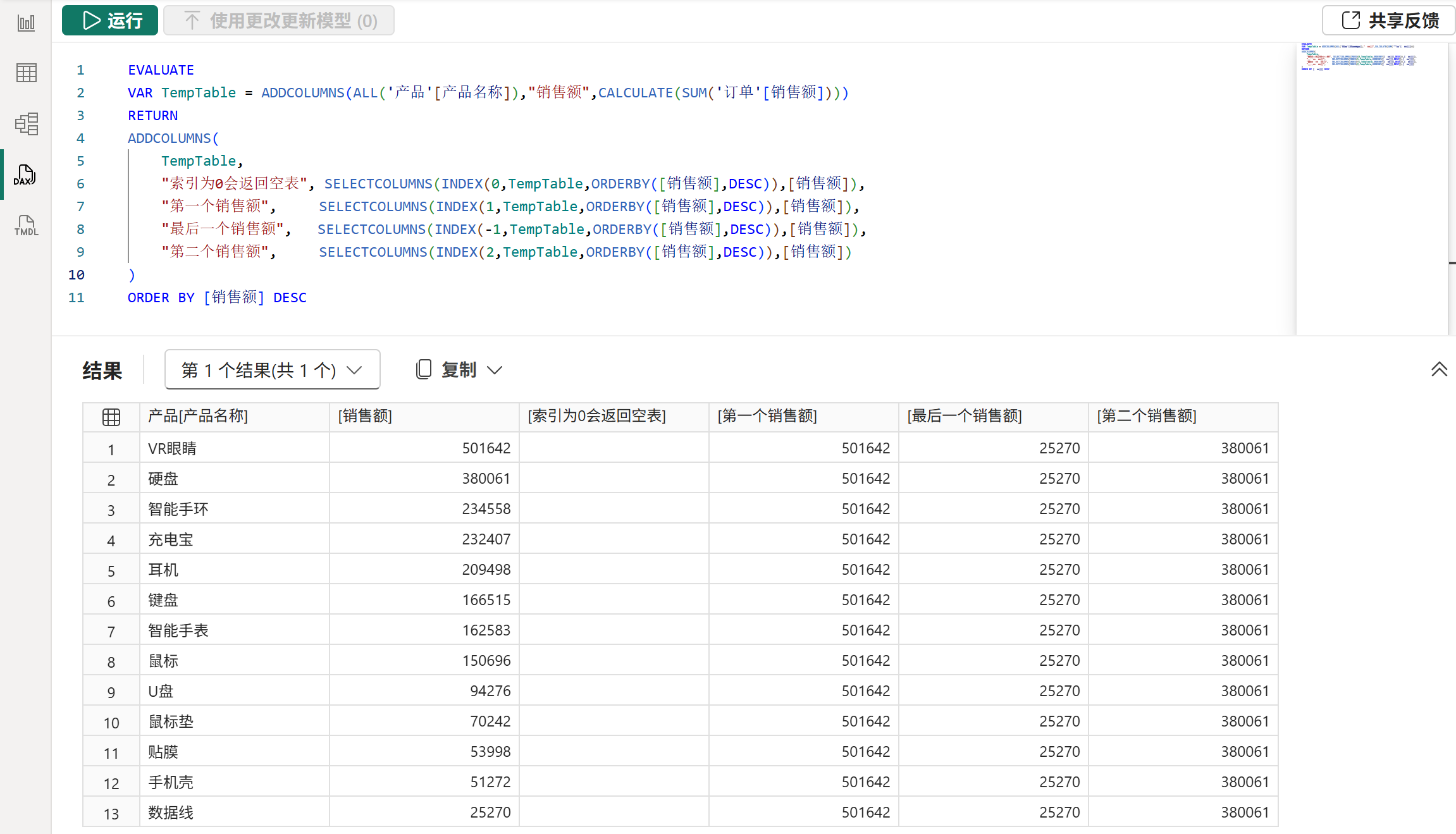
2、INDEX函数
语法:
INDEX( <position>[, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )作用:
在经过partitionBy参数分区和orderby参数排序后的relation参数的表中,在当前分区中返回position参数指定的第几行。
position参数不能省略,它可以是任意整数,当其为正数时,1为第一行,2为第二行,以此类推;当其为负数时,-1为最后一行,-2为倒数第二行,以此类推;当其等于0或空时,返回无任何数据的空表。
注意:
1、当position参数指定的行数过大,超出了第一行或最后一行时,将会返回空表。
2、由于INDEX函数采用的是绝对位置,因此不会涉及到当前行的判断与绑定,具体请参考后文的计值流程和应用语义部分。
示例:
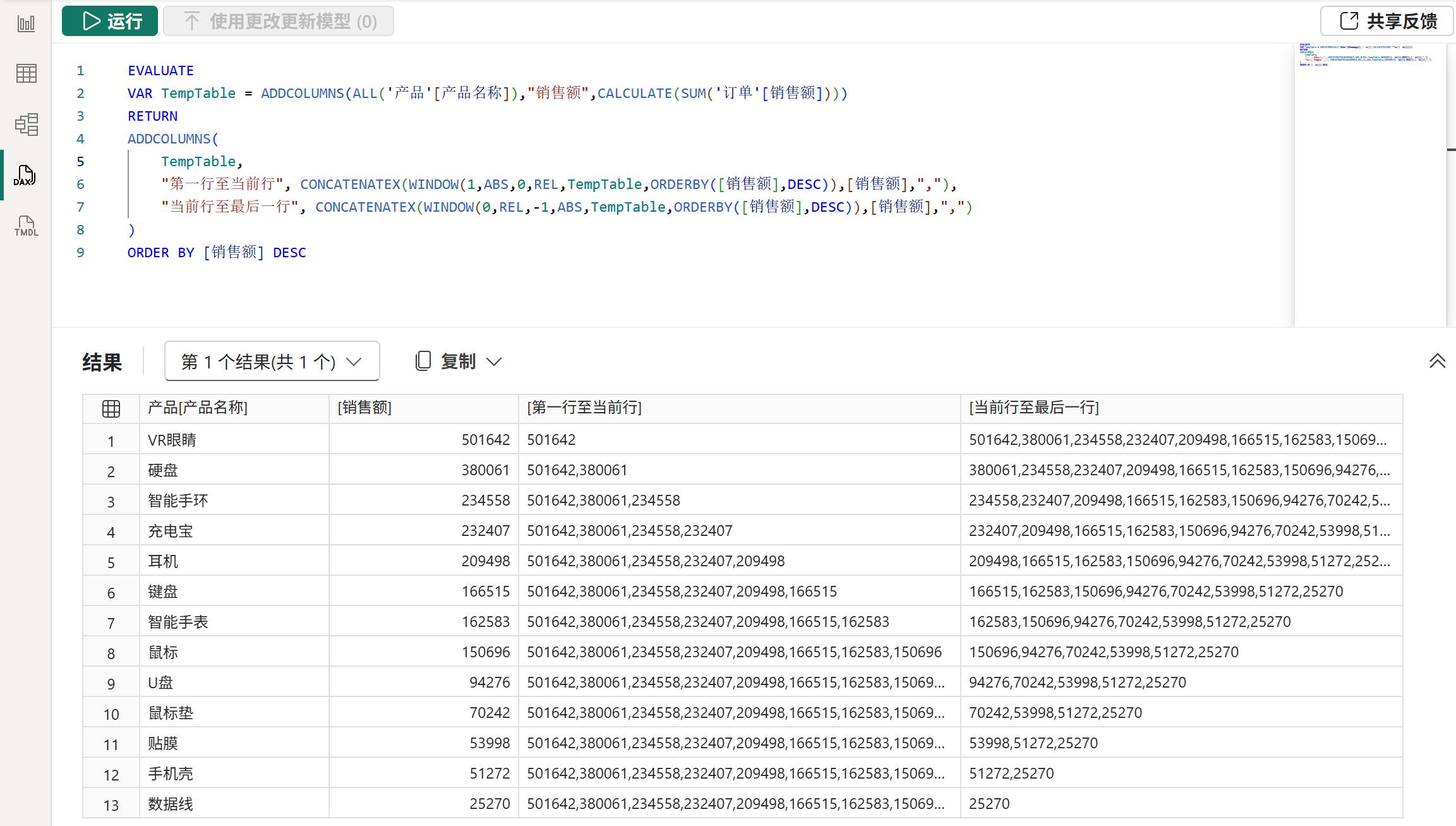
3、WINDOW函数
语法:
WINDOW( from[, from_type], to[, to_type][, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )作用:
在经过partitionBy参数分区和orderby参数排序后的relation参数的表中,在当前分区中返回from参数与to参数指定的行区间中包含的所有行。
其中,from参数与to参数均有两种类型,由from_type参数与to_type参数控制,一种是绝对位置ABS,另一种则是相对位置REL,类型参数省略时默认为REL。
- 当类型为
ABS时,from参数与to参数可以是任意整数,当其为正数时,1为第一行,2为第二行,以此类推;当其为负数时,-1为最后一行,-2为倒数第二行,以此类推;当其等于0或空时,会被解释为第一行。 - 当类型为
REL时,from参数与to参数可以是任意整数,将基于当前行向上或向下移动指定的行数,0代表不移动,正数代表向下移动,负数代表向上移动。
注意:
1、from参数指定的是行区间的起始行,to参数指定的是行区间的结束行,结束行必须大于或等于起始行,不能出现倒挂,否则会返回空表。
2、from参数与to参数指定的行区间中,若起始行位于第一行之前,则会被设置为第一行。同样,若结束行位于最后一行之后,则会被设置为最后一行。换句话说就是只会返回指定的行区间中具有的行,如果指定的行区间的起始行与结束行均位于第一行之前或最后一行之后,那么将返回空表。
3、当from_type参数与to_type参数为REL时,会基于当前行进行偏移。而当前行有时候可能并不止一行,当存在多个当前行时,会基于各个当前行进行一次行区间的确定并返回,最终返回合并且去重后的结果。关于当前行的确定,具体请参考后文的计值流程和应用语义部分。
示例:
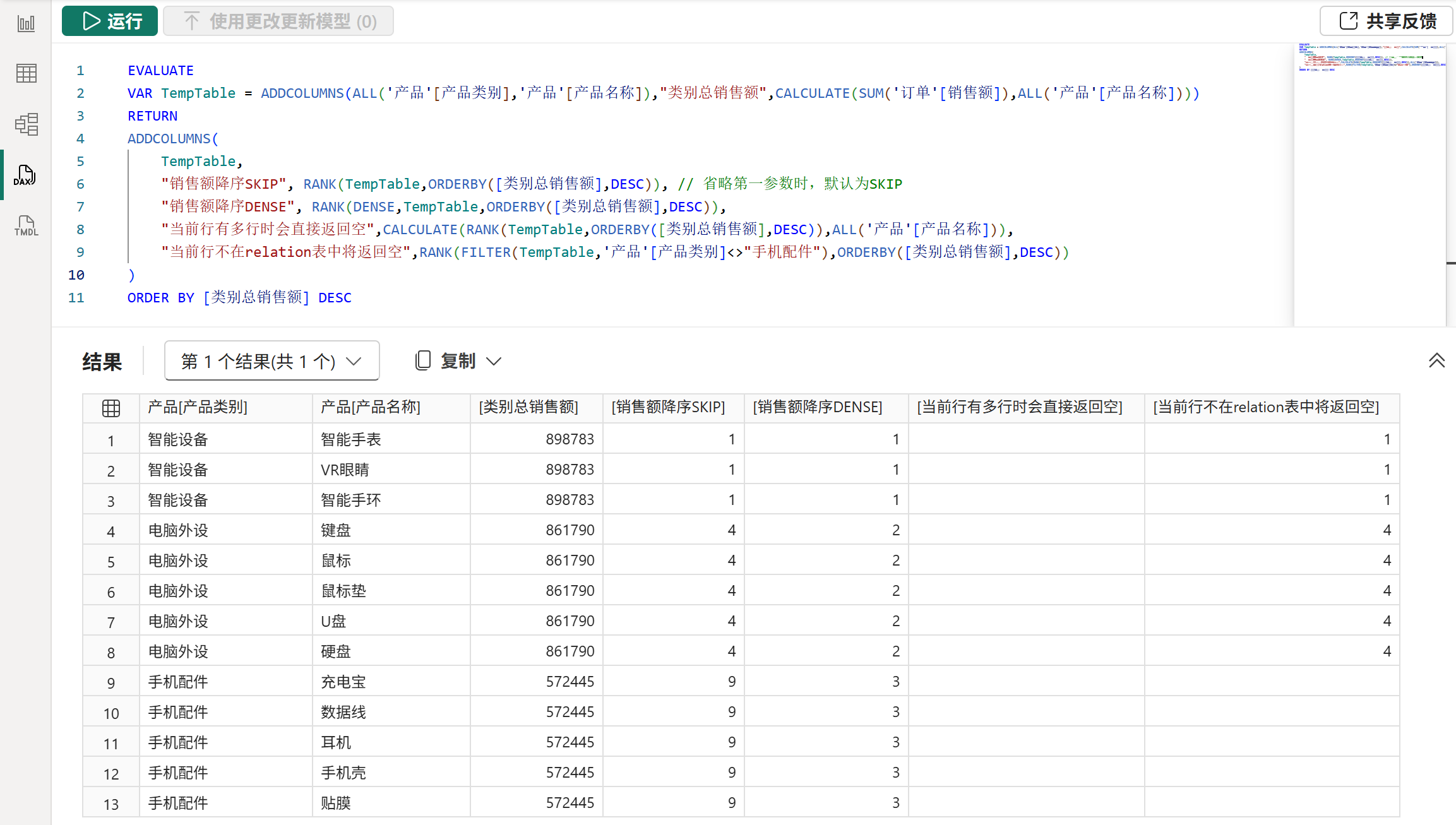
4、RANK函数
语法:
RANK( [<ties>][, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )作用:
首先,使用partitionBy参数和orderby参数对relation参数的表进行分区和排序,然后DAX引擎会根据各个分区中的排序结果设置对应的排名,最后返回外部计值环境中的当前行的排名。
其中,ties参数是一个枚举值,可以控制出现并列排名时的排名样式,可选的枚举值有:SKIP与DENSE,如果省略该参数则默认为SKIP。
注意:
RANK函数与之前一直就有的RANKX函数的作用虽然都是排名,但他们的排名机制不太一样。RANK函数的排名机制是在一个已经排好名次的表中找到当前行,进而再获取到当前行对应的排名,属于事先排名。而RANKX函数的排名机制则是在给定的一堆数中看看指定的数应该排在哪里,属于实时排名。
因此,对于RANK函数而言,如果当前行并不在它事先就排好名次的表中,那么它将无法获取到对应排名,将返回空。而RANKX函数则不同,随便给它一个数,它都会从要参与排名的一堆数中找到这个数应该所处的排名。
由于这两个函数的排名机制不同,因此各有应用场景,不会出现其中一个被完全代替的情况。比如,RANKX函数除了可以用来对序列内的值排名外,还可以对序列外的值进行排名,也可以应用在价格区间等场景中。而RANK函数由于遵循窗口函数的计值流程,其orderBy参数可以很方便的按多个条件进行排序,并且它的排名机制可以避免浮点运算带来的误差,保证排名的准确性,而这又是RANKX函数做不到的。
总而言之,这两个排名函数都很有用,可以根据自己的掌握情况来决定使用哪一个。不过一般情况下,如果不需要对序列外的值进行排序,那还是比较推荐使用RANK函数的。
另外,RANK函数需要依赖外部计值环境中的当前行来寻找其对应的排名,但当前行有可能并不止一行,若当前行不止一行时,RANK函数将直接返回空值。关于当前行的确定,具体请参考后文的计值流程和应用语义部分。
示例:
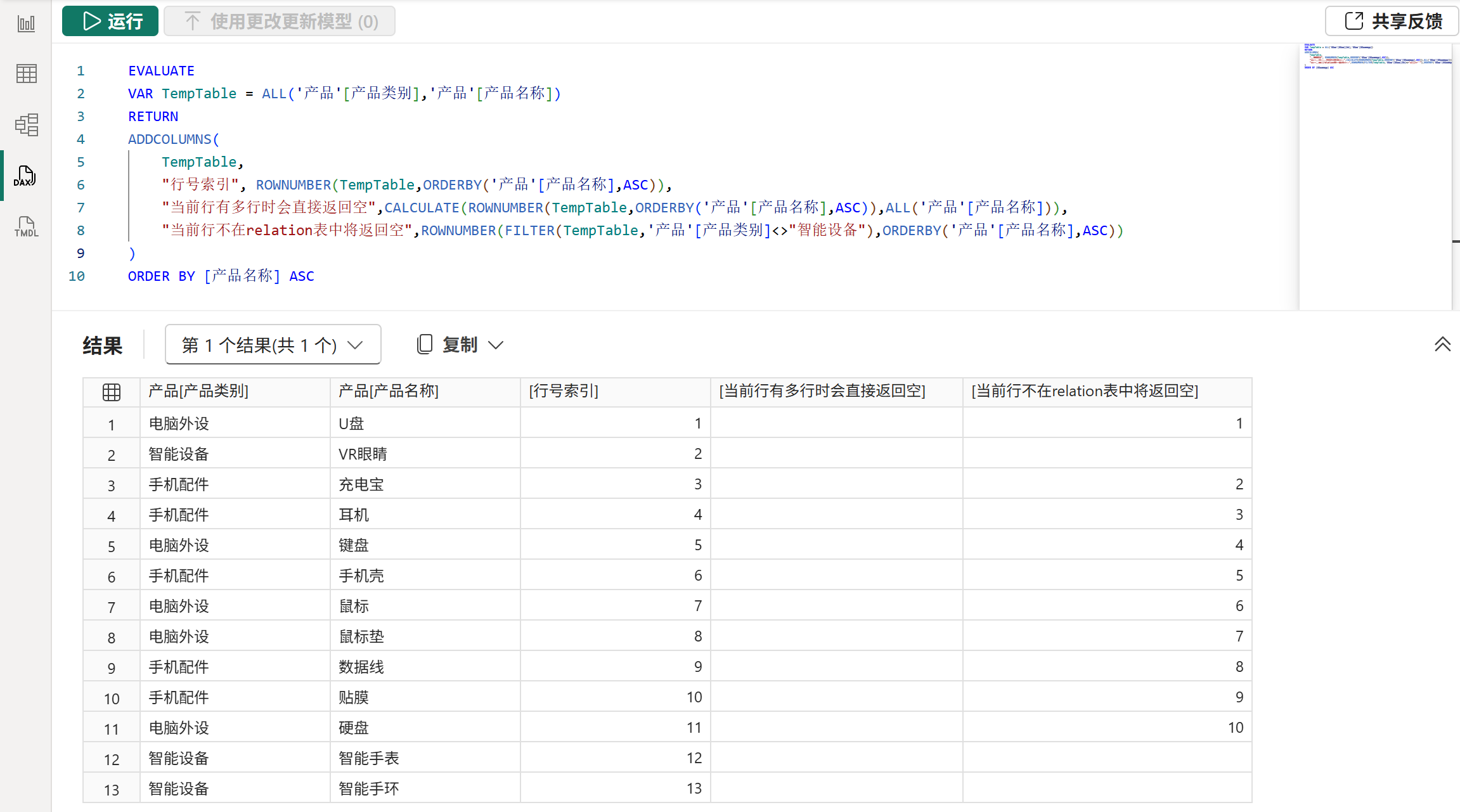
5、ROWNUMBER函数
语法:
ROWNUMBER( [<relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )作用:
首先,使用partitionBy参数和orderby参数对relation参数的表进行分区和排序,然后DAX引擎会根据各个分区中的排序结果给每一行设置一个连续且唯一的行号,最后返回外部计值环境中的当前行的行号。
注意:
1、ROWNUMBER函数并不是像函数名称那样会给表的每一行添加能唯一标识行的行号索引,添加行号索引的工作应该由ETL工具完成,ROWNUMBER函数做不到这样的效果,它的行为与作用有点类似RANK函数,将在一个已经添加好行号的表中找到当前行,进而再获取到当前行对应的行号。
2、ROWNUMBER函数的设计目的是为了给依赖复合主键的表添加一个键列,它会假定relation参数提供的表不存在重复行,并且也会在执行期间主动验证唯一性。如果不能保证提供给relation参数的表一直都不存在重复行,那么最好不要使用它,因为当后面新添加的数据出现重复行时就会报错。
3、由于ROWNUMBER函数会假定relation参数提供的表不存在重复行,并主动验证唯一性,因此该函数在relation参数上的限制与其他的窗口函数都不一样,具体请参考后文的限制与注意事项部分。
4、对于ROWNUMBER函数而言,如果当前行并不在它事先就排好行号的表中,那么它将无法获取到对应行号,将返回空。
5、ROWNUMBER函数需要依赖外部计值环境中的当前行来寻找其对应的行号,但当前行有可能并不止一行,若当前行不止一行时,ROWNUMBER函数将直接返回空值。关于当前行的确定,具体请参考后文的计值流程和应用语义部分。
示例:
窗口函数的计值流程
理解应用语义
完整计值流程的示例演示
限制与注意事项
窗口函数的应用示例
窗口函数的应用并不是本篇文章的主题,因此这里就简单给出一些使用到窗口函数的应用示例,更多的应用场景可以自行探索或参考其他资料。
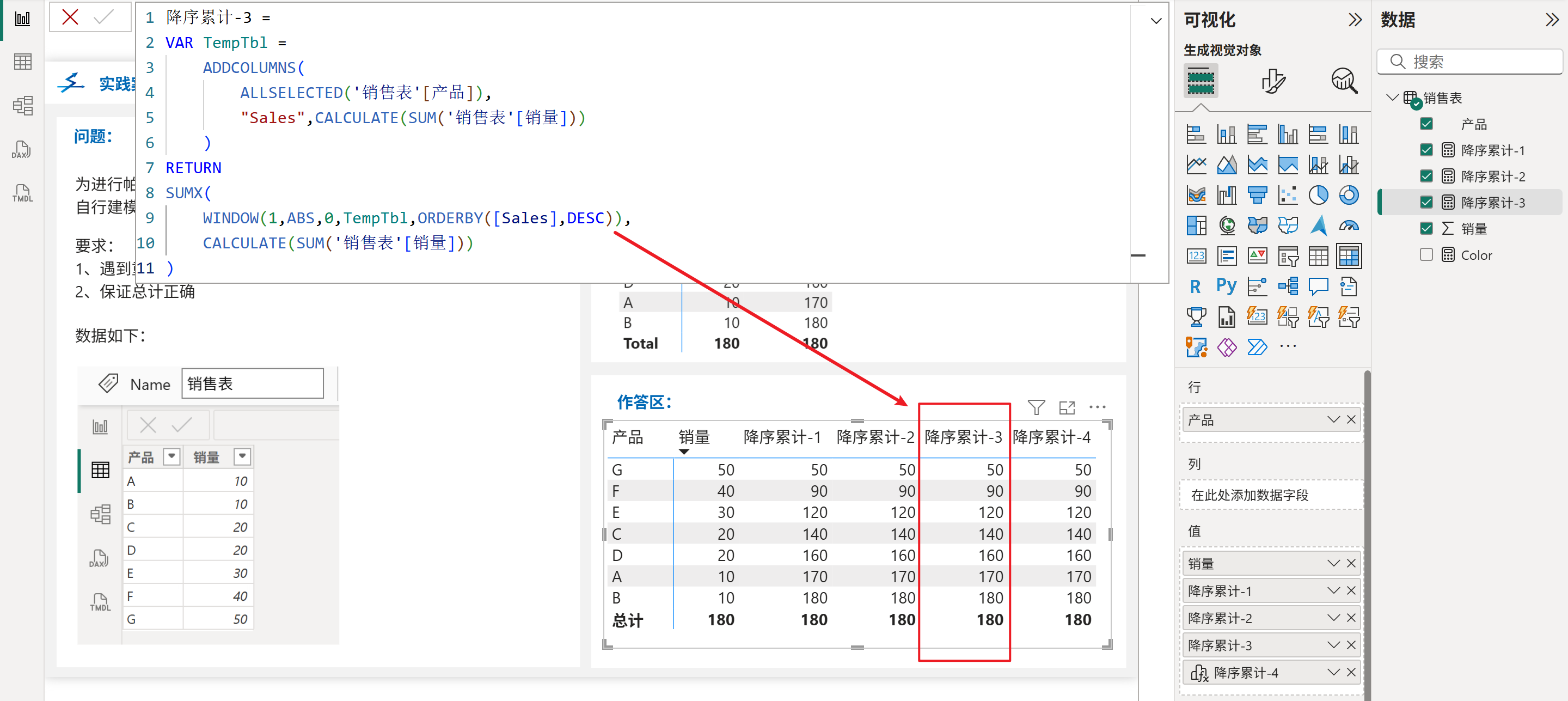
1、计算累计值,如下图所示:
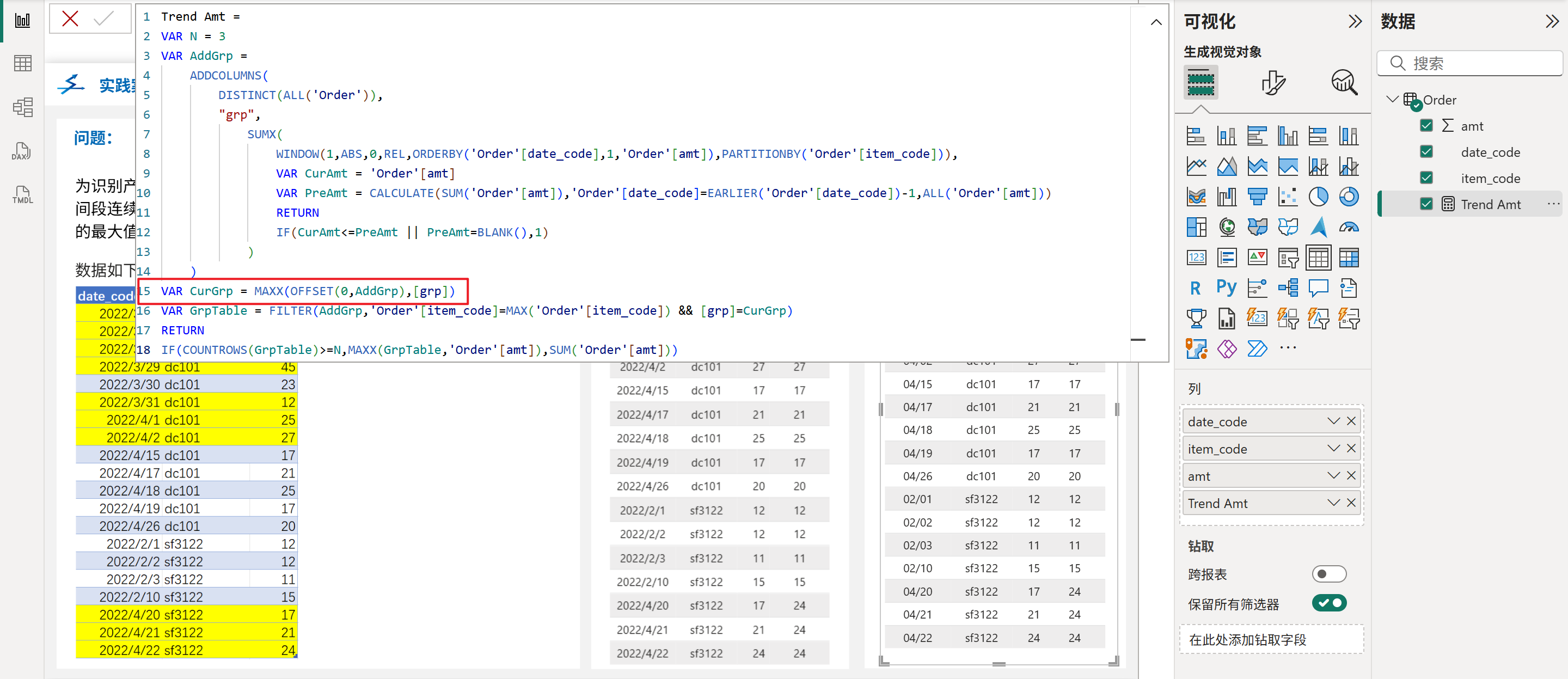
2、快速获取矩阵行标签在变量表中的分组,如下图所示:
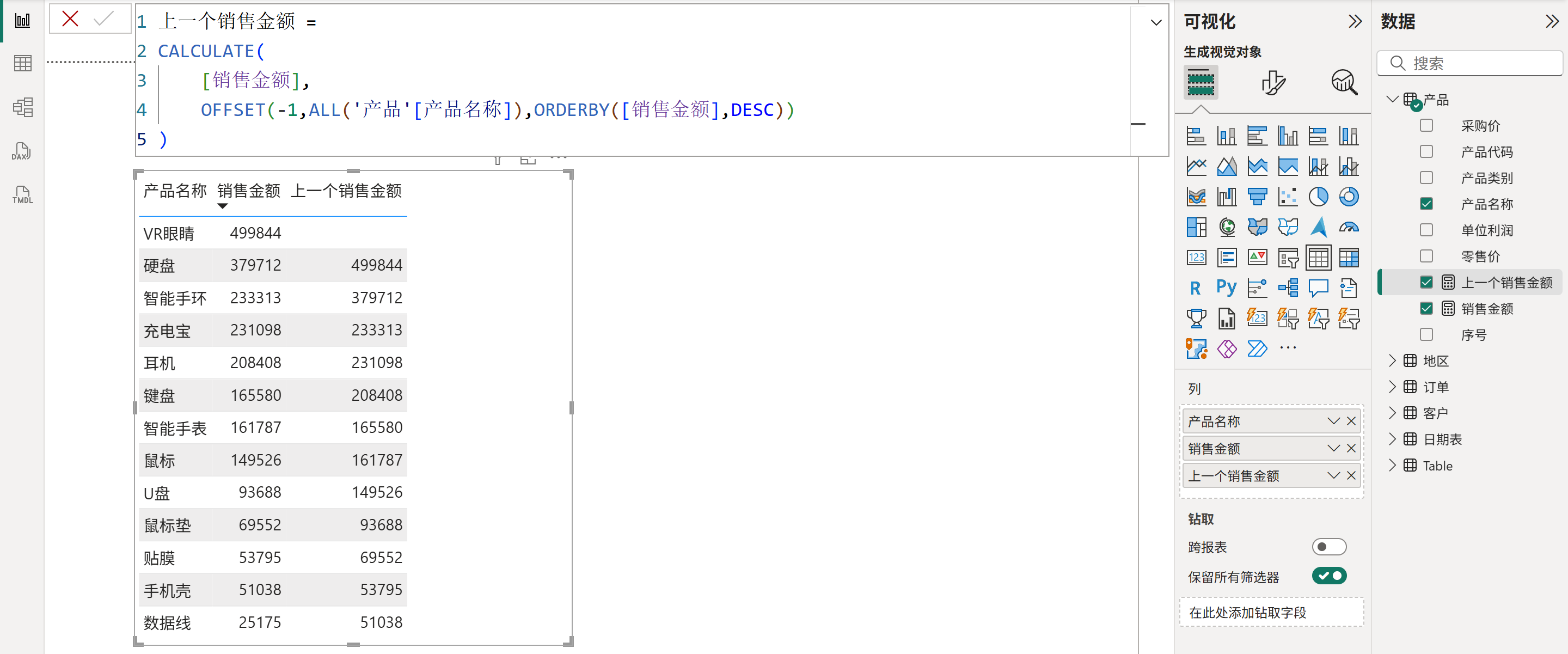
3、基于矩阵当前行进行偏移,获取上N行或下N行的指标的值,如下图所示:
4、获取某个类别下的第N个值,如下图所示:
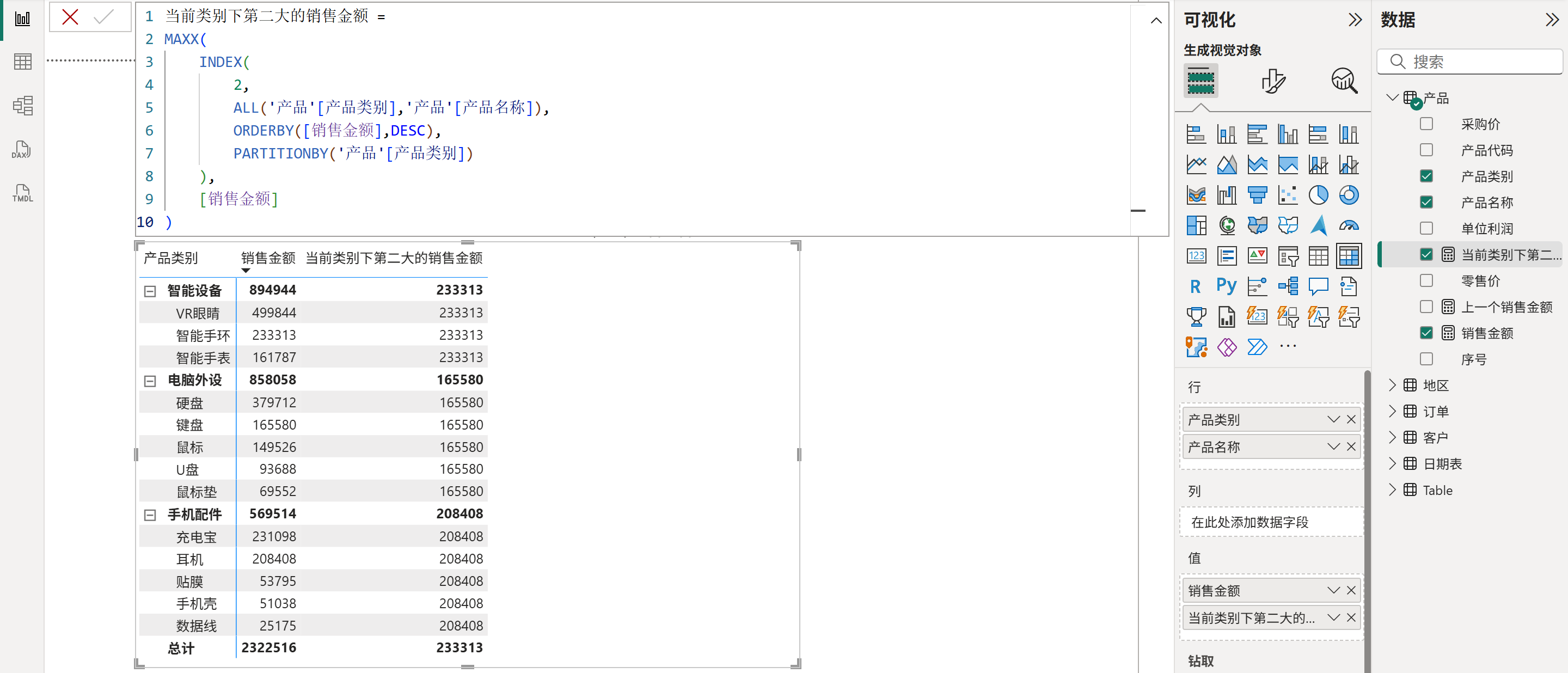
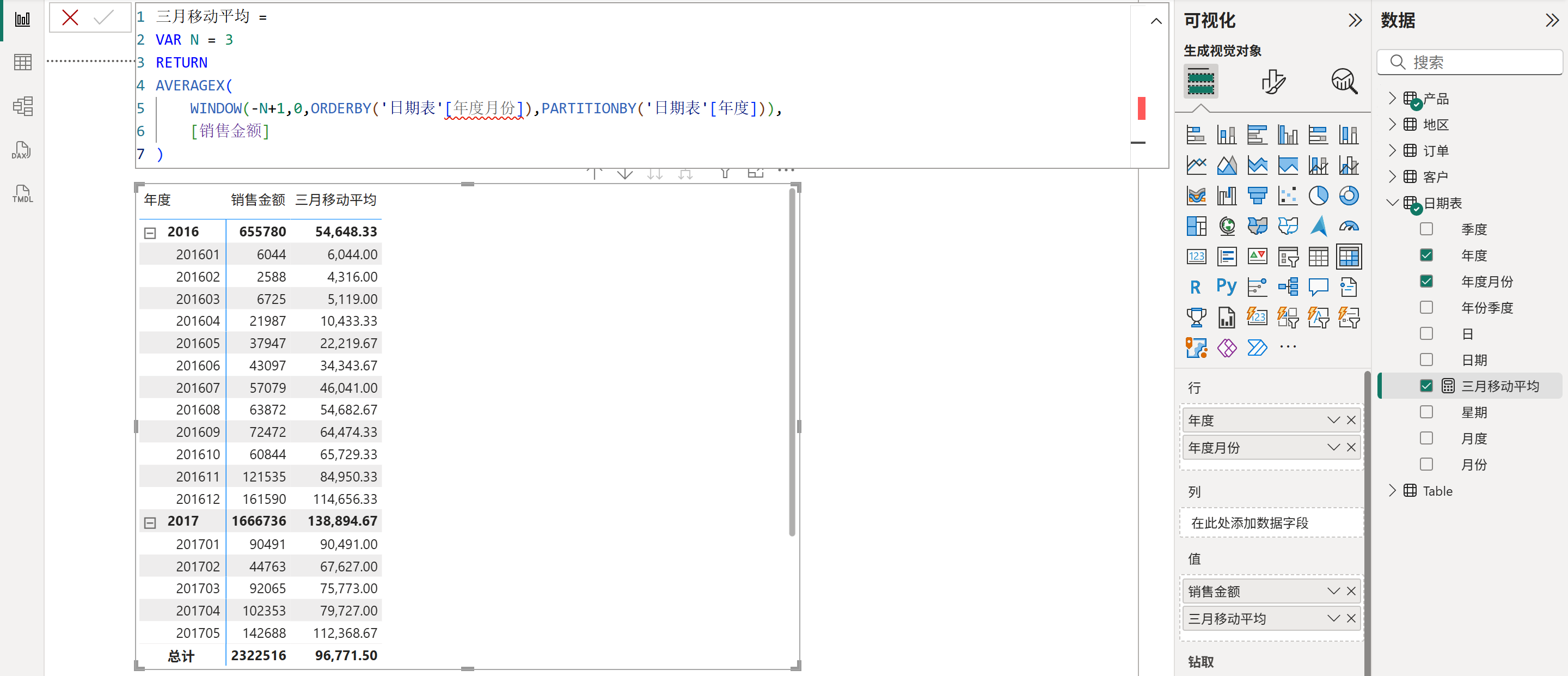
5、计算移动平均值,如下图所示:
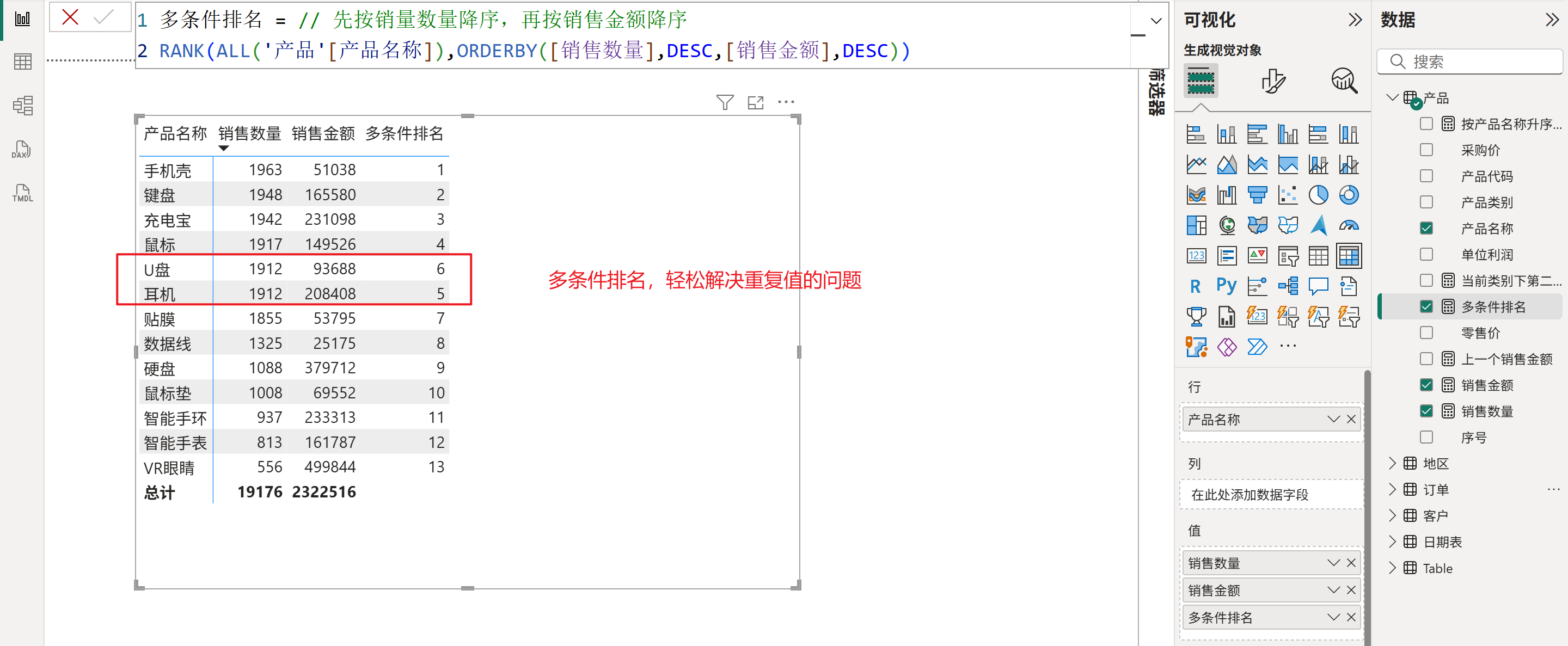
6、多条件排名,如下图所示:
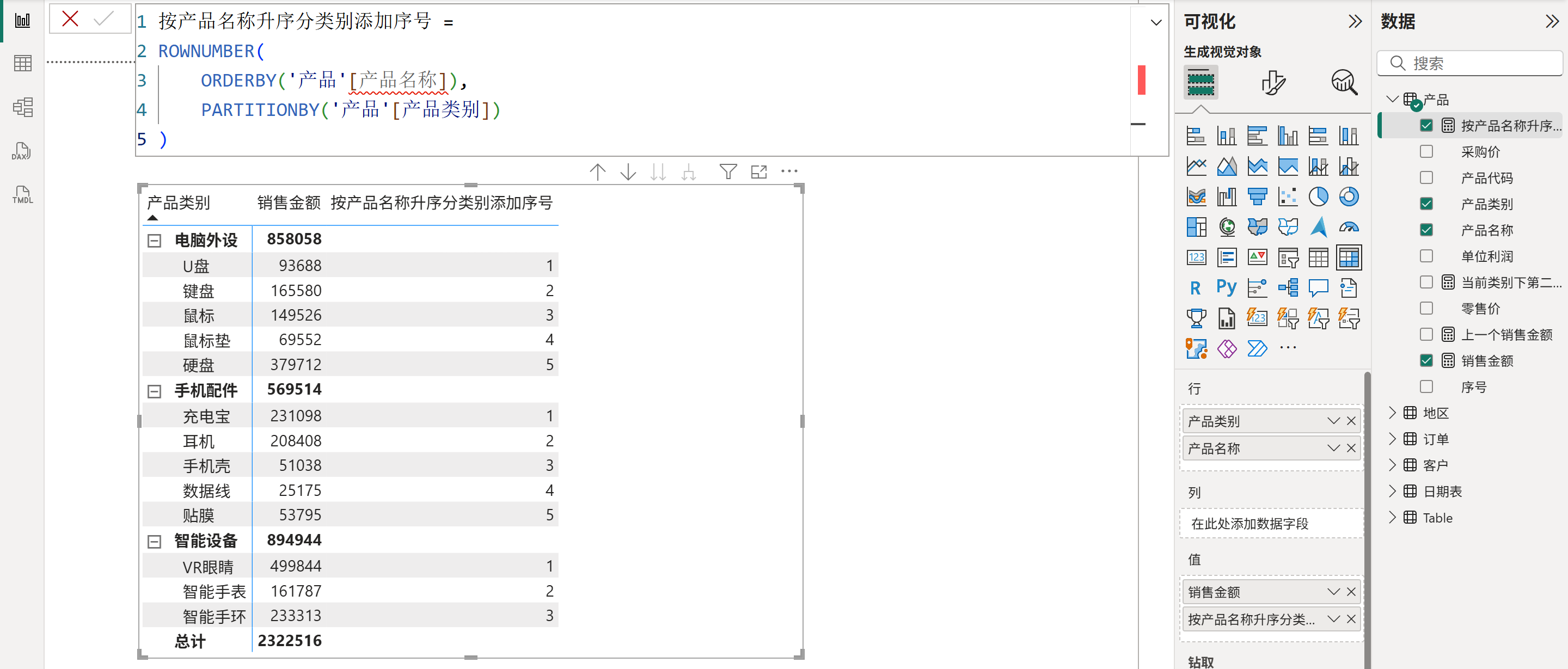
7、添加行号,如下图所示:
总结
恭喜阅读到这里!相信此刻的你,已经对PowerBI中窗口函数的全貌有了深刻且系统的理解。从基础概念、核心语法,到各种成员函数的异同、计值流程,再到应用语义、关键限制与注意事项,每一环节都详细拆解,层层递进。而且还穿插了丰富的案例与边界探讨,让你真正“知其然,更知其所以然”!
窗口函数的引入,极大地简化了某些场景的复杂运算逻辑,让过往繁琐的DAX代码变得精炼高效且优雅。但与此同时,也需警惕主键、去重、分区、排序等蕴含的细节和“坑”,以避免在实际业务中踩雷。



















