
数据沿袭(Data Lineage)是一个很重要且设计很巧妙的特性,它决定了各种筛选器能否筛选模型中的数据,以及使用什么姿势来筛选。同时,DAX引擎以一种自然且直观的方式来处理数据沿袭的复杂性,在编写表达式时通常不需要考虑它,以至于大多数用户可以在不了解它的情况下使用它。
理解数据沿袭
数据沿袭其实就是一个标记,DAX引擎会给模型中的所有列都分配一个唯一且不同的标记。通过这个标记,即使在进行了各种转换与处理后,也可以正确的识别出数据源头,即数据是来自哪个列的。
你可能会好奇数据来自哪个列有什么意义,这其实决定着这些数据在作为筛选器时能否筛选模型中的表,以及筛选的范围等。比如下图所示的度量值中,似乎CALCULATE函数的内部筛选器参数并没有生效,度量值始终返回总销售额。
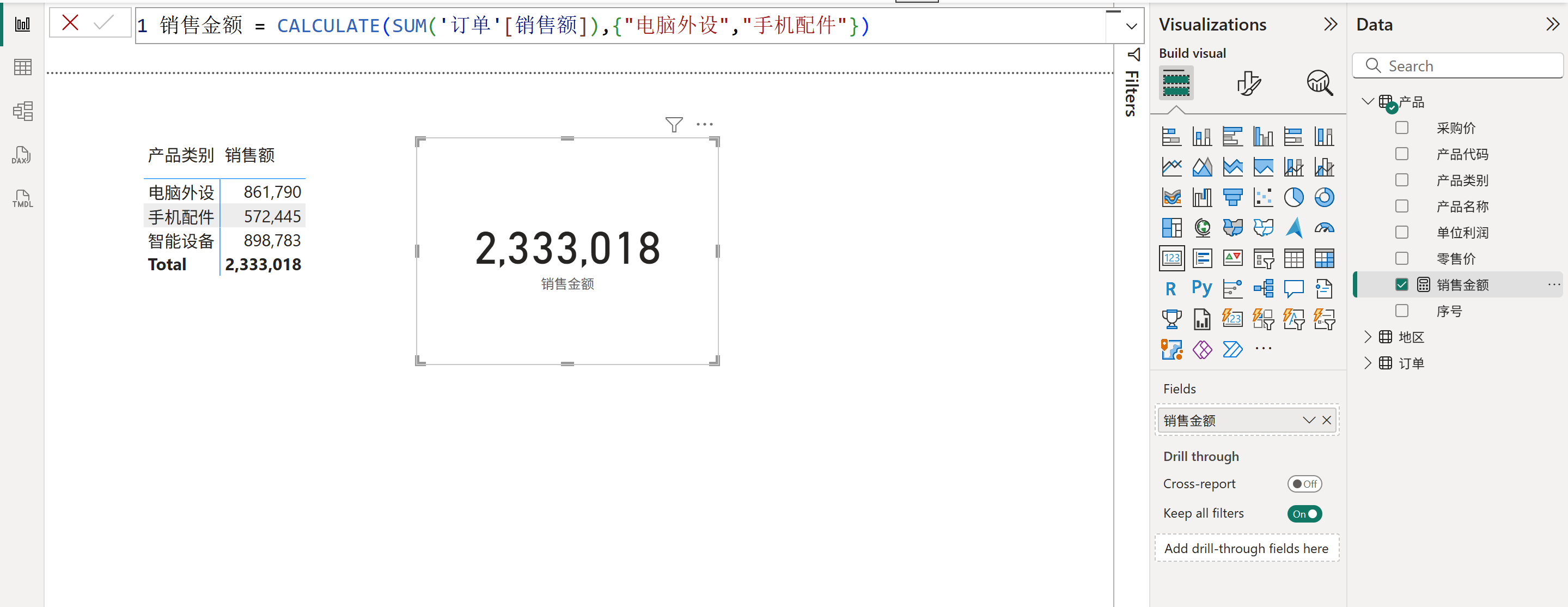
这是因为,在CALCULATE函数的内部筛选器中使用了由表构造器语法生成的表,而表构造器生成的表是匿名的,即表中的各个列不存在数据沿袭,所以使用该匿名表来作为筛选器时是无法筛选模型中的数据的。
虽然在我们人的眼中看来,“电脑外设”和“手机配件”都是产品类别,但是在DAX引擎的眼中它们只是两个字符串,而且不存在数据沿袭,那么DAX引擎就不知道它们来自哪个列,所以不会把这两个字符串和产品类别列关联起来。而筛选器能够筛选某个表,是因为该表的扩展表上包含这个筛选器所属的列,再由于列是表不可分割的一部分,不会出现各个列独自被筛选的情况,因此表中某个列被筛选会导致整个表被筛选。所以,当出现了一个不含数据沿袭的匿名列上的筛选器时,由于它是匿名的,所以模型中的每个表都说不认识它,都说它不是来自于我这个表,这就导致了模型中的每个表都无法被它筛选,使得模型中每个表的可见数据都是所有数据,而这就是上面这个度量值总是返回总销售额的原因。
如果使用FILTER函数改写上面这个度量值,那么该度量值则能正确计算出两个产品类别的销售额,如下图所示:
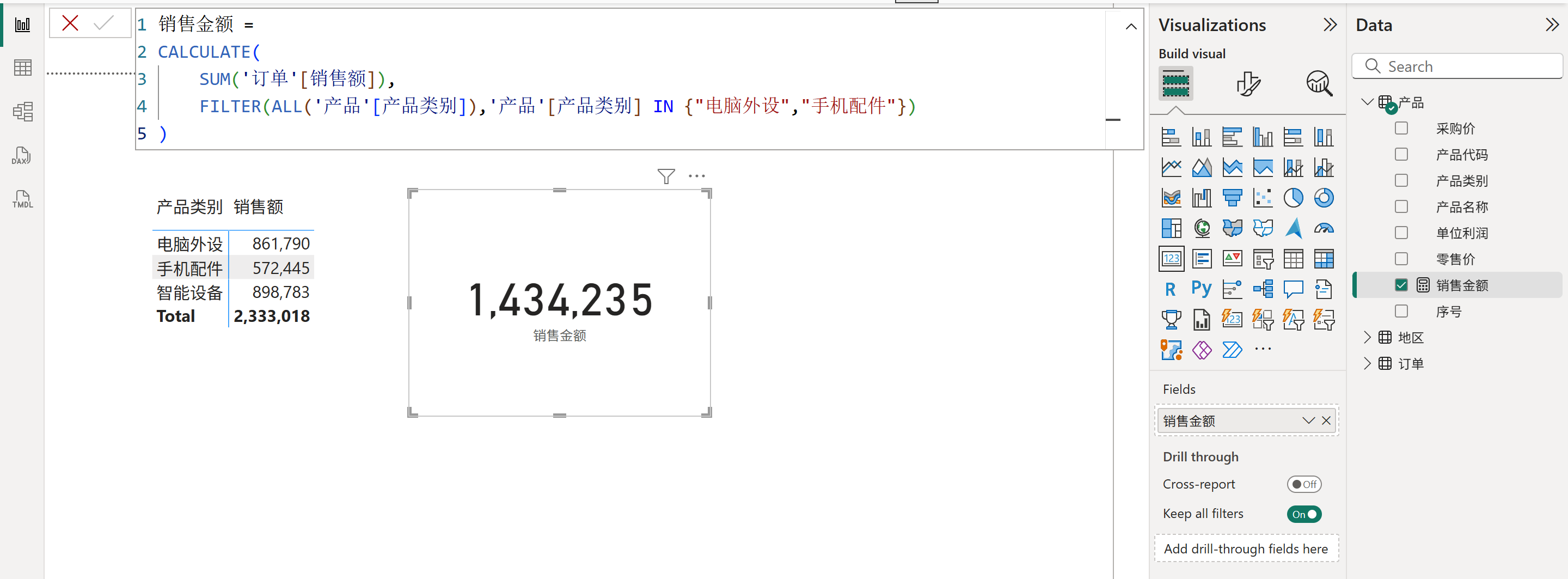
此时,该内部筛选器不再是来自匿名列上的筛选器,而是来自模型中的产品类别列上的筛选器,即它拥有数据沿袭,而数据沿袭的标记会指向模型中的产品类别列。然后当它去筛选模型中的数据时,就会以产品表上的产品类别列的身份去筛选数据,筛选的范围则与模型关系有关,它可以从产品表开始,沿着模型关系的指向去筛选其他表。
另外要注意的是,某个筛选器能够筛选的范围是与其数据沿袭所指的列有关的,如果数据沿袭指向了一个没有与其他表连接任何关系的孤立的表上的列,那么它能够筛选的范围也就仅仅只是这个孤立的表,而不能筛选模型中的其他表,因为不存在模型关系,所以无法传递筛选器。
比如下图所示的,当FILTER的第一参数的列引用是来自一个孤立的表:产品2,那么这时的内部筛选器虽然是有数据沿袭的,其指向了产品2上的产品类别列,但由于产品2这个表没有与其他表连接关系,所以该内部筛选器无法筛选订单表,也就导致了度量值最终返回了总销售额。
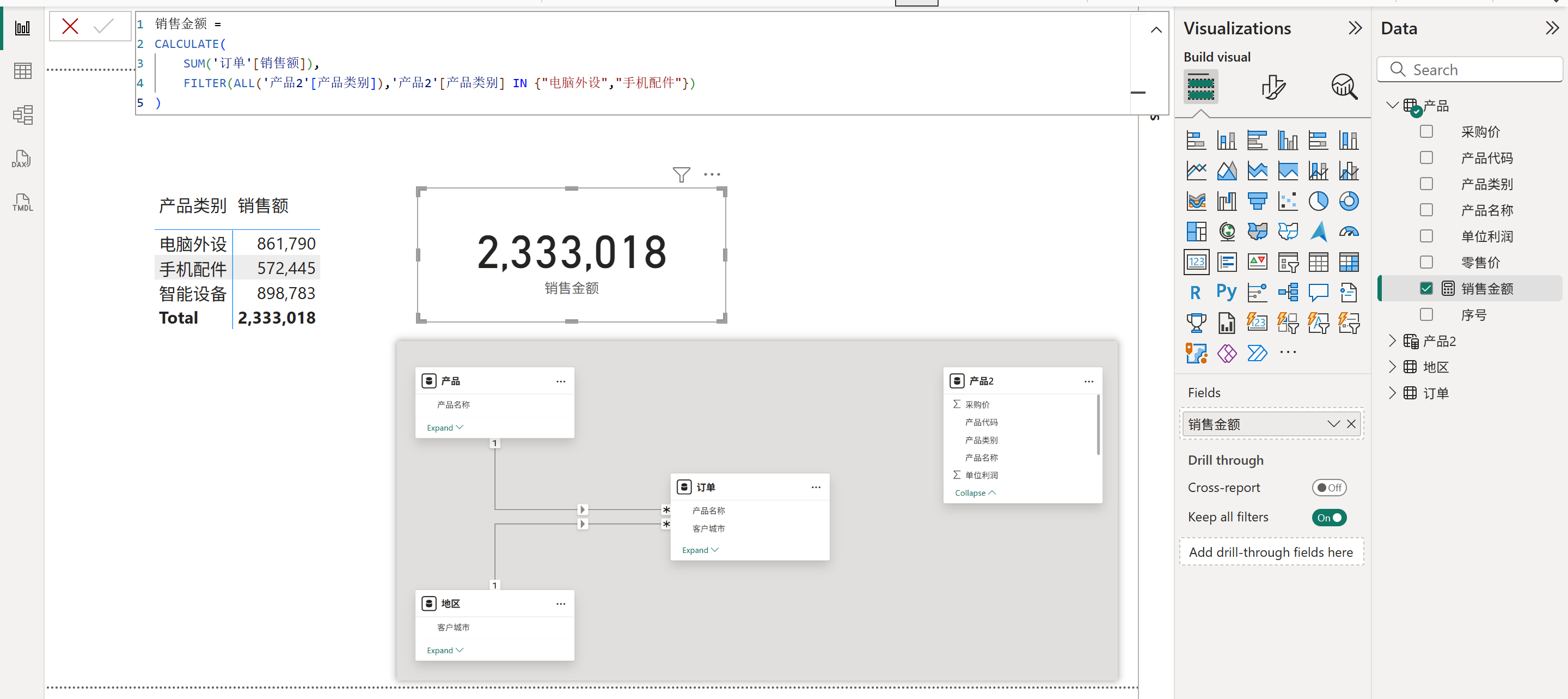
这个例子中返回的也是总销售额,与最开始的无数据沿袭的例子中的结果一致,但是它们得到这个结果的原因却是不一样的,这一点要注意区分。
从上面案例的对比中,应该也可以理解数据沿袭的作用了,它虽然只是一个说明数据属于哪个列的标记,但它能够决定筛选器能否筛选模型中的数据以及筛选的范围,所以是非常重要的。
数据沿袭的继承
下面来看一下数据沿袭的继承,即哪些操作或函数可以继承数据沿袭,哪些操作或函数则不可以。
由于DAX引擎采用了一种自然且直观的方式来处理数据沿袭的复杂性,即使在进行了各种转换与处理后也可以正确的识别出数据源头,所以基本绝大多数表函数都能够继承数据沿袭。而不能继承数据沿袭的操作则比较少,具体如下:
- ADDCOLUMNS函数的所有派生列都不具有数据沿袭
- SELECTCOLUMNS函数中,除直接引用列外还额外使用了任意函数或运算符的派生列都不具有数据沿袭
- UNION函数中,合并的两个列的数据沿袭若不一致也会导致合并后的列丢失数据沿袭
- 由表构造器、DATATABLE、ROW等函数或语法所返回的表都不具有数据沿袭
- 数据沿袭是针对表中的列的,因此所有返回标量值的函数的返回结果都不具有数据沿袭
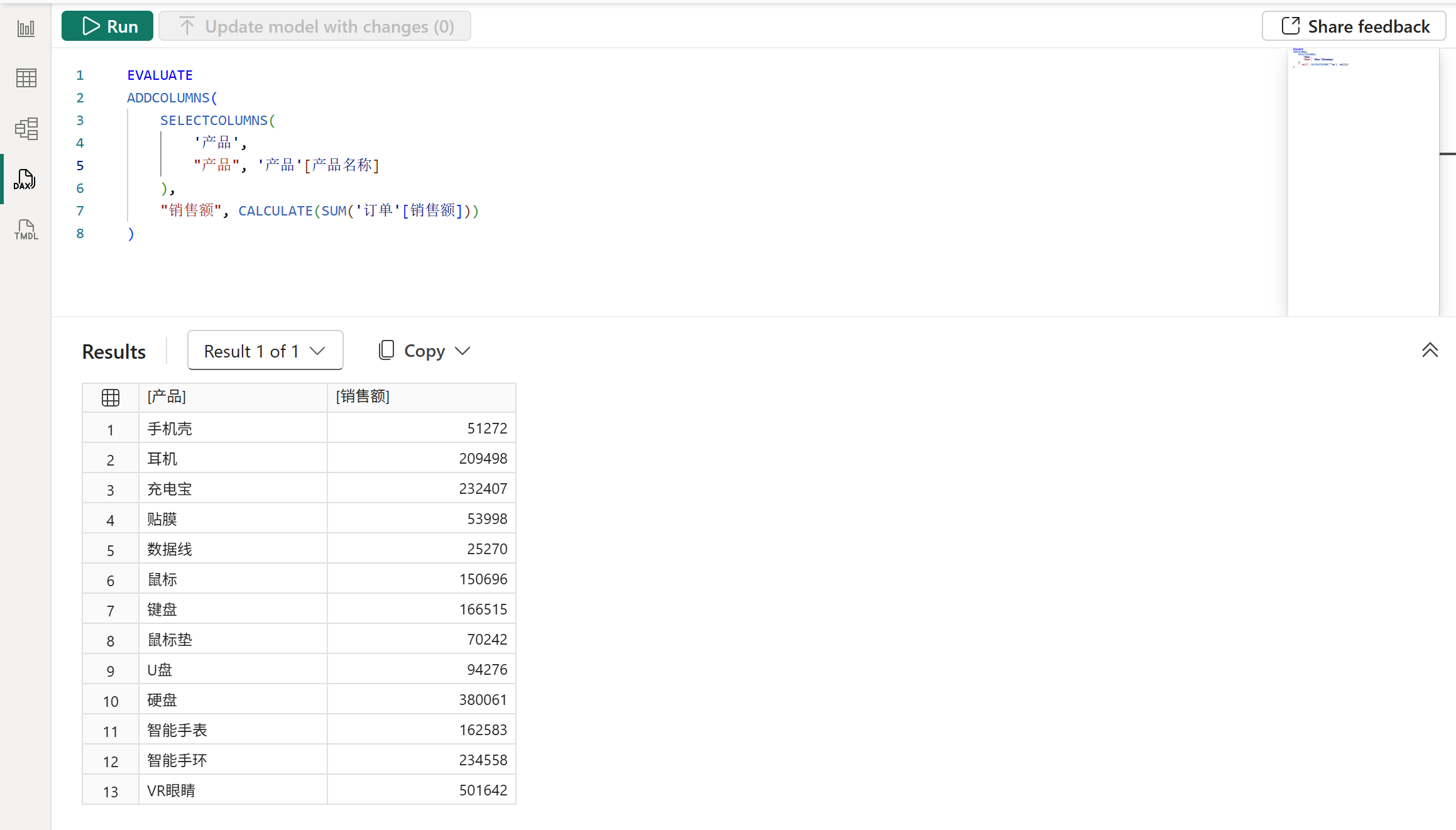
如下图所示,在SELECTCOLUMNS函数中,如果是直接引用列的话,那么是具有数据沿袭的,体现为行上下文转换后得到的筛选器能够正常筛选订单表,从而得到各个产品的销售额。
但如果在SELECTCOLUMNS函数中额外使用了其他函数或运算符,比如给产品名称的列引用拼接了一个空字符串,那么虽然值看起来是一样的,但实际上已经不具有数据沿袭了,最终导致行上下文转换后的筛选器无法筛选模型中的数据,最终返回了总销售额,如下图所示:
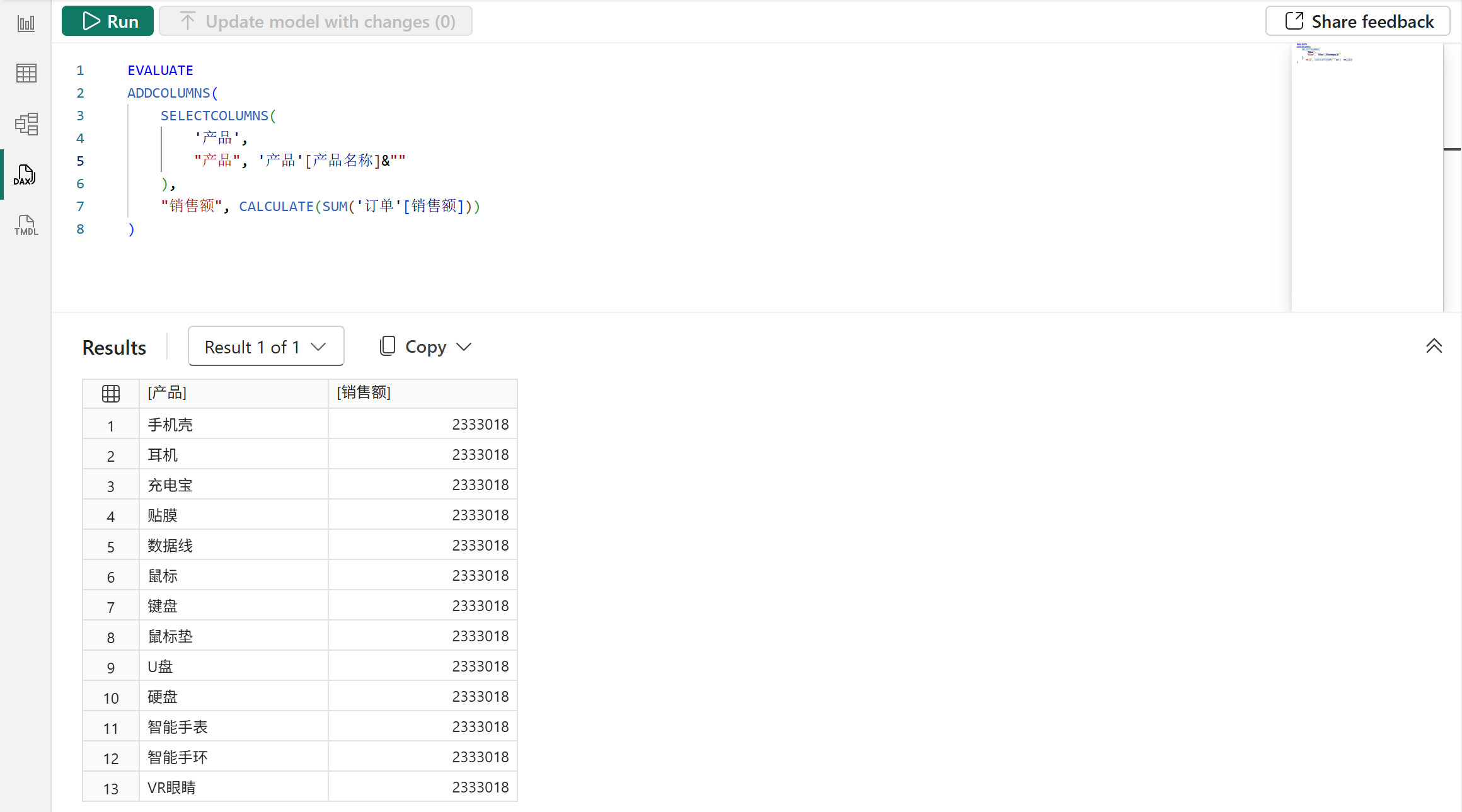
此外,在ADDCOLUMNS函数中添加的任何派生列都是不具有数据沿袭的,即使是直接的列引用,如下图所示:
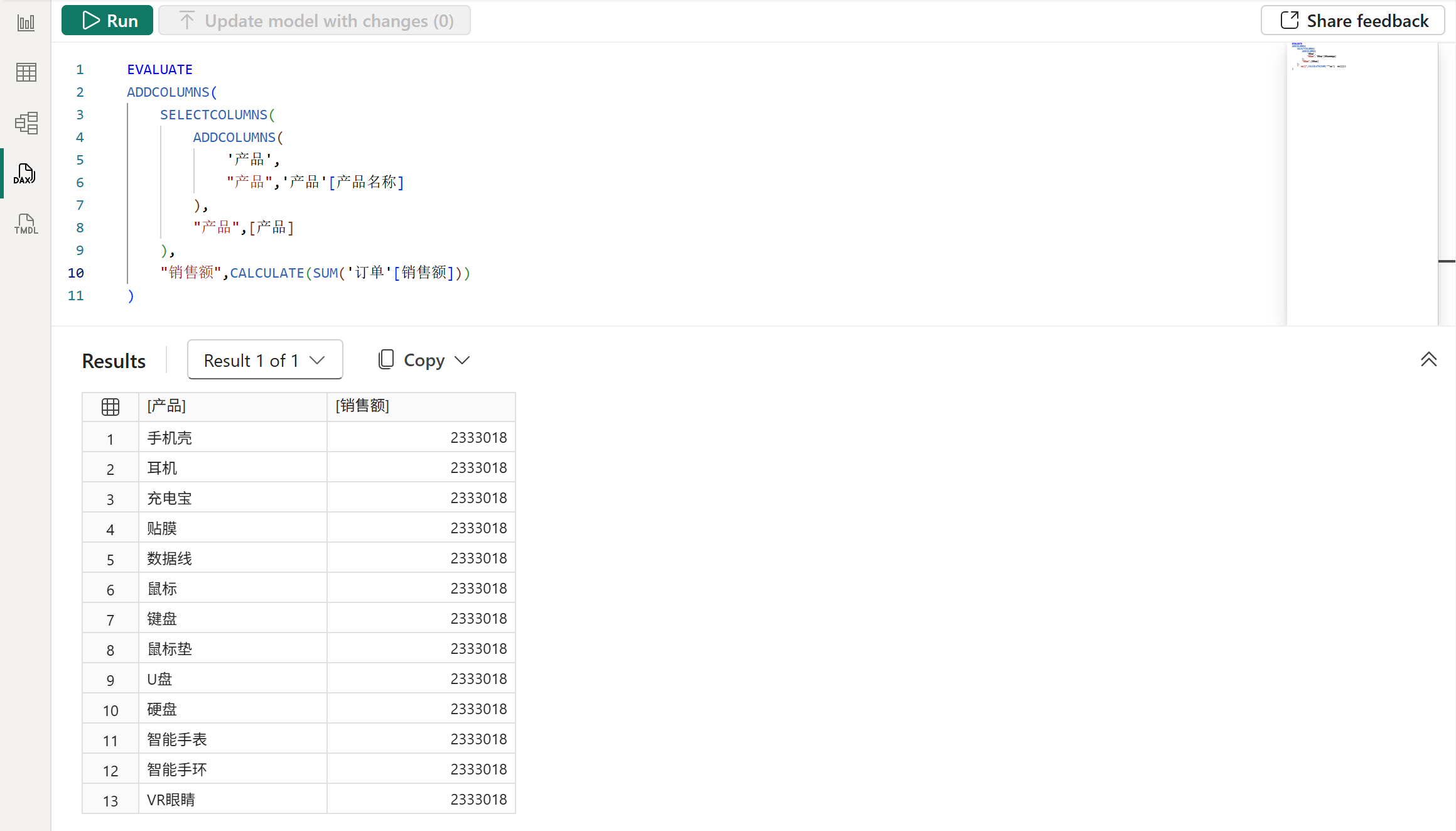
其中使用了SELECTCOLUMNS函数去提取ADDCOLUMNS函数添加的派生列,然后SELECTCOLUMNS函数中是直接引用列的,因此会继承数据沿袭,但是由于ADDCOLUMNS函数添加的所有派生列都是无数据沿袭的,也就是说源头本身就无数据沿袭,因此后边继承得到的也是无数据沿袭,所以行上下文转换后得到的筛选器无法筛选模型中的数据,最终返回了总销售额。
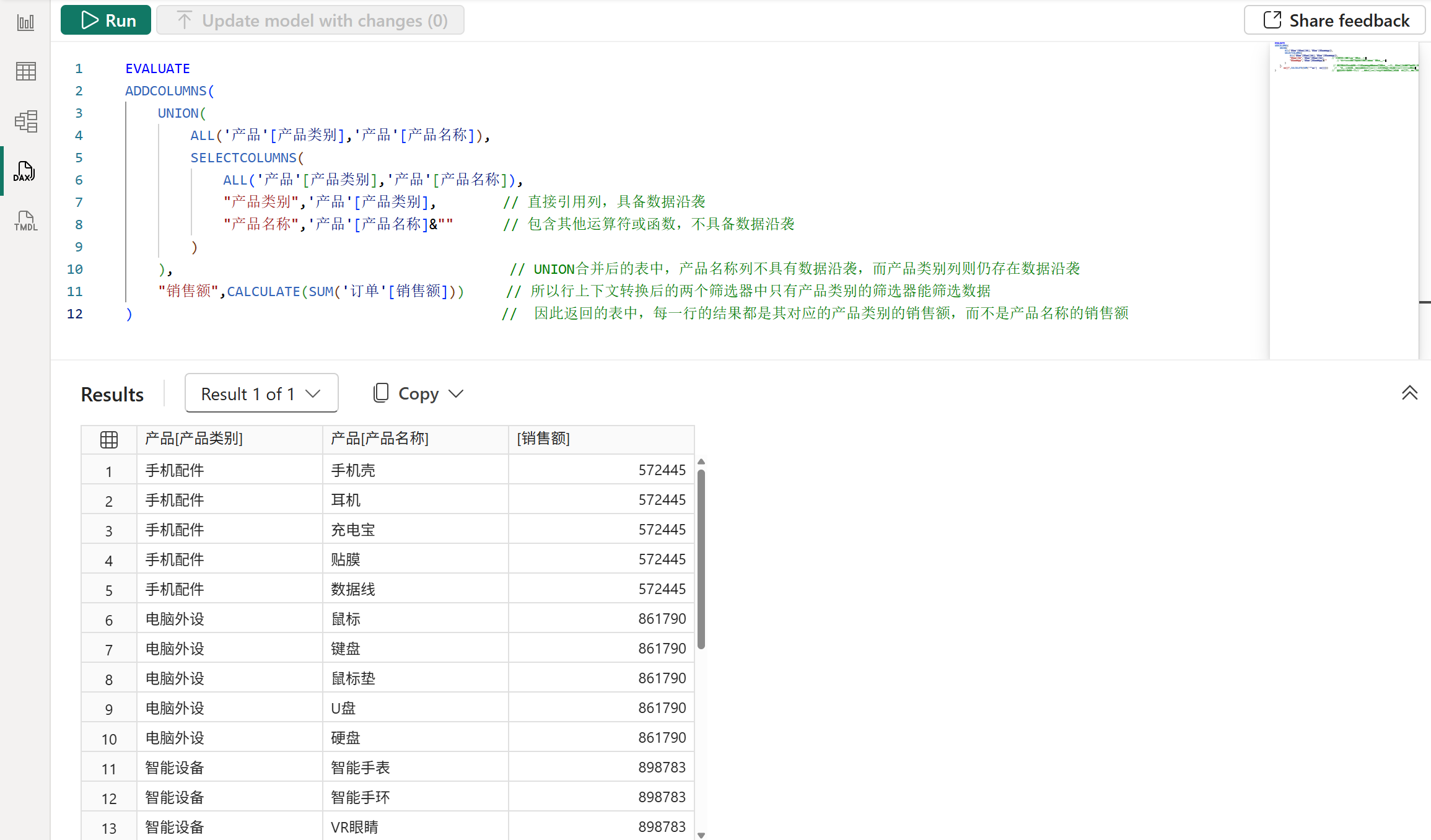
再比如下图所示的查询,在UNION函数中合并的两个表中,对应位置的列如果数据沿袭不一致,那么合并后的表中的这个列就会丢失数据沿袭。
然后还有一个注意事项是要注意的,即:数据沿袭与列名和列值都无关,如下图所示:
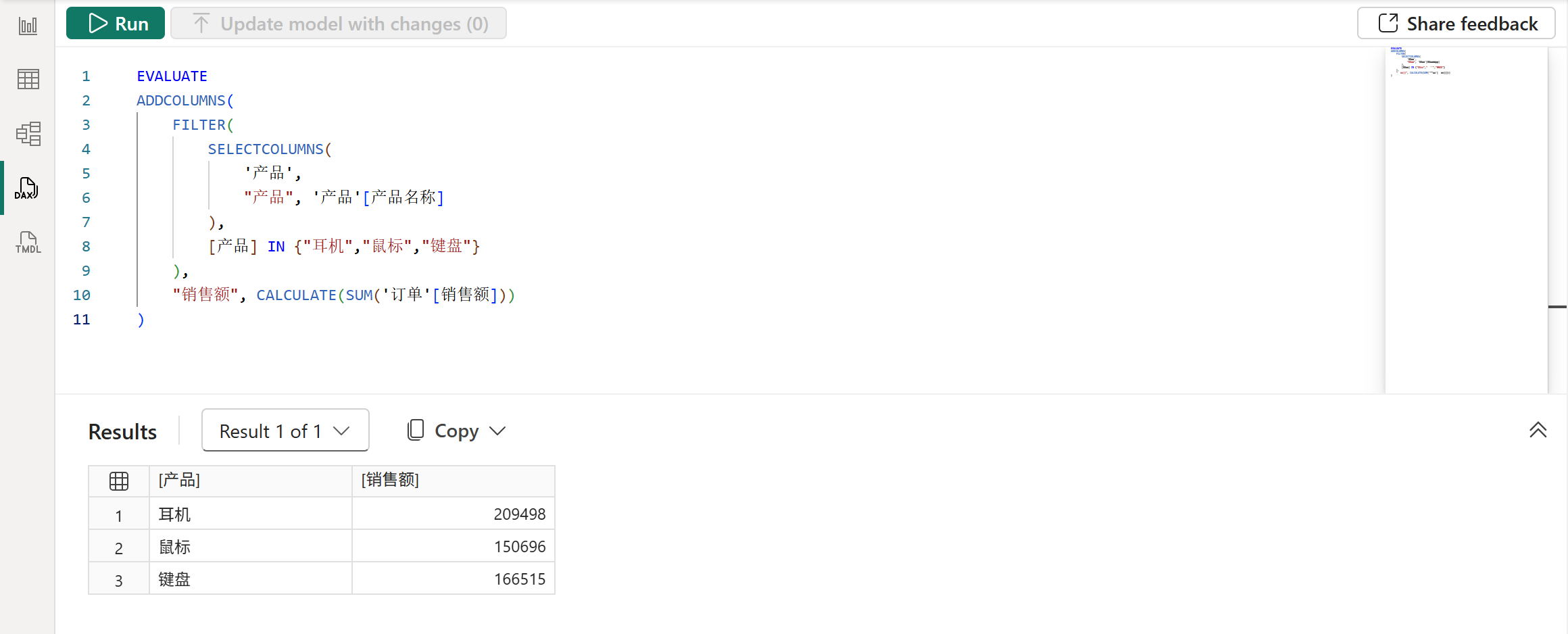
以上查询中,使用了SELECTCOLUMNS函数将产品名称重命名成产品,并使用了FITLER函数对其进行筛选过滤,但这都不会影响它的数据沿袭,所以行上下文转换后的筛选器可以正常筛选各个产品的对应销售额。
数据沿袭的更改
数据沿袭是可以被更改的,当某个筛选器的数据沿袭被更改后,该筛选器就可以借用更改后的数据沿袭的标记所代表的列的身份来筛选模型中的数据。
更改筛选器的数据沿袭一共有两种方法,一种是借助TREATAS函数直接修改数据沿袭,另一种则是筛选器转移的方式,即:从数据沿袭目标列上过滤出原始筛选器筛选的值,然后再将过滤后的目标列作为筛选器。注意:筛选器转移并不能直接修改数据沿袭,虽然它能达到同样效果,但实际上起作用的对象是新的筛选器。
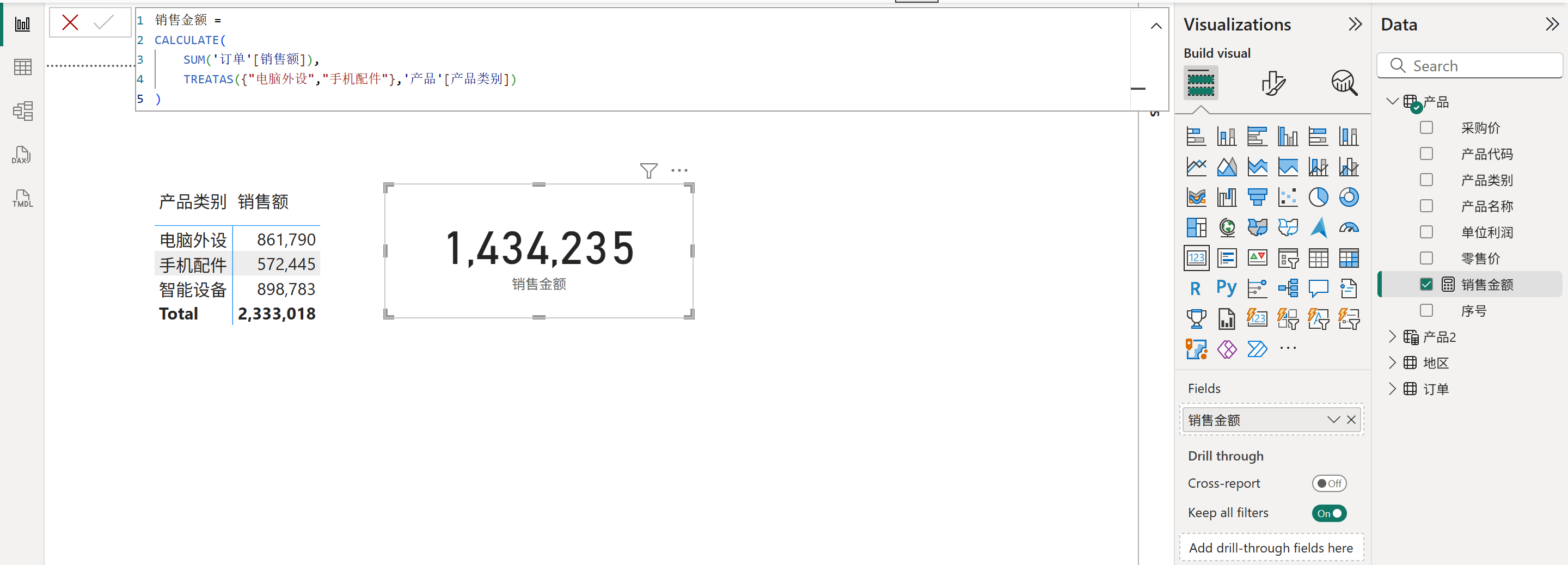
1、TREATAS函数
语法:TREATAS(table_expression, column[, column[, column[,…]]])
作用:指定第一参数的表达式返回的表的各个列的数据沿袭来源列,将按列顺序依次设置,因此后续参数中指定的列数必须与第一参数返回的表的列数一致,不能多也不能少。另外,如果第一参数的表的各个列的值在其指定的数据沿袭来源列中不存在,那么该值将被忽略,表现为从第一参数的表中直接过滤掉该值所在的行。
比如文章开头的匿名筛选器案例,可以直接用TREATAS函数来赋予数据沿袭,如下图所示:
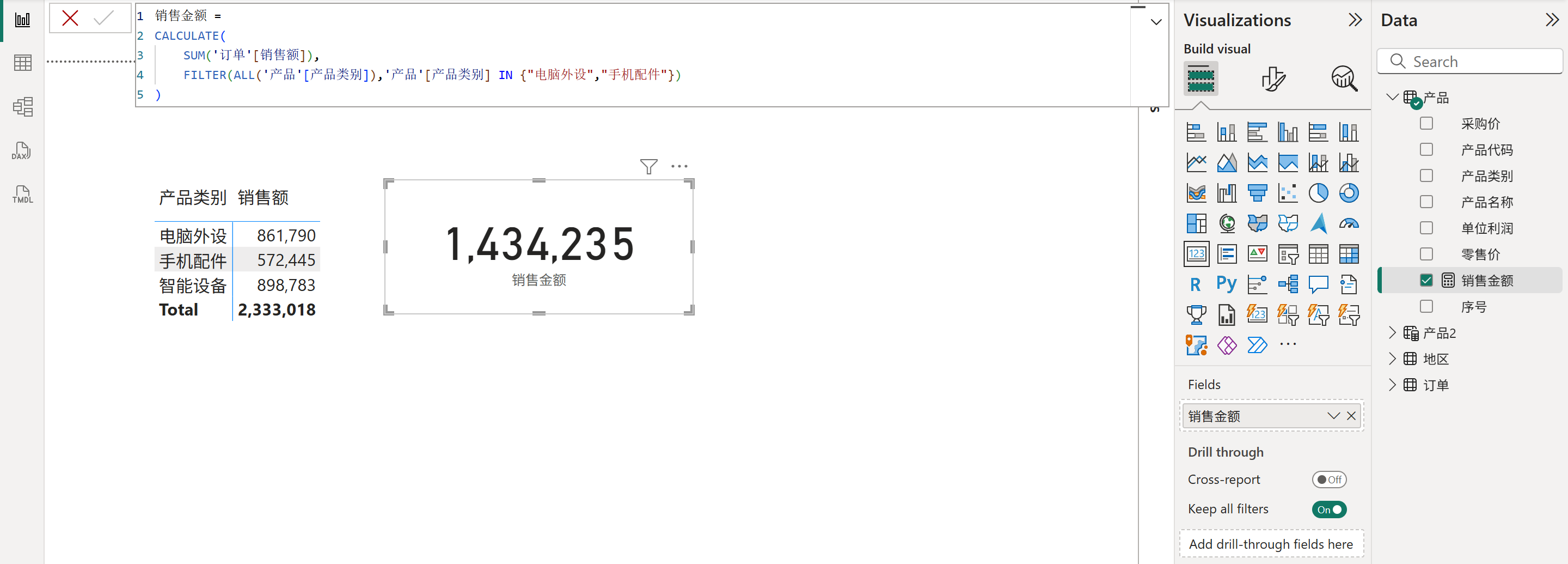
2、FILTER函数
FILTER函数的方法属于筛选器转移的方法,先从数据沿袭的目标列里筛选过滤出对应值,然后再将其作为筛选器。具体如下图所示:
3、INTERSECT函数
INTERSECT函数属于集合函数,将返回两个参数中的表都存在的值,即取交集,它同样属于筛选器转移的方法,具体如下图所示:

以上三种方法中,只有TREATAS函数才能直接修改数据沿袭,其他两种筛选器转移的方法其实是用本来就有数据沿袭的新筛选器去替代旧筛选器,本质上它们是不能修改数据沿袭的。
另外,如果需要修改的筛选器不是标准筛选器,而是含有多列的固化筛选器,那么筛选器转移的方法就不再好用了,此时最佳的方法就是使用TREATAS函数直接修改数据沿袭。
应用案例
下面来看一个TREATAS函数的实战案例,比如想要计算各个产品的首次销售额的汇总,那么平时可能会这么写,如下图所示:

这个方法并没有问题,是很经典的写法,迭代获取每个产品的首次销售日期,然后再筛选日期等于首次日期的销售额。但是该方法并不够优雅和高效,因为总共发生了两次行上下文转换,一次是计算首次销售日期,另一次则是计算首次销售额时。
如果可以先计算出每个产品对应的首次销售日期,并将其作为筛选器的话,那么将会减少一次行上下文转换,更加高效,如下图所示:
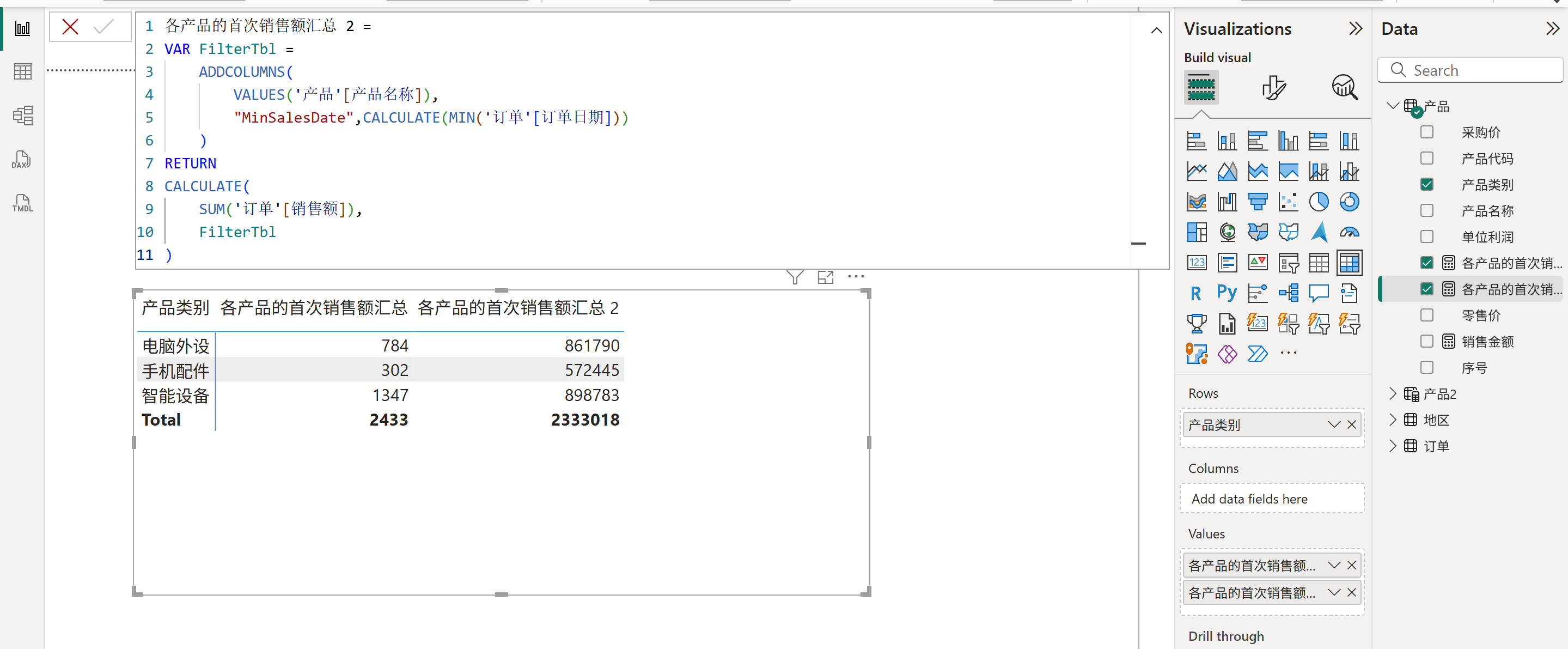
可惜的是,由于ADDCOLUMNS函数添加的所有派生列都不具有数据沿袭,因此导致最终计算销售额时只筛选了产品而没有筛选日期,所以返回的结果是错误的。
那么这个思路难道不可行吗?答案是可行的,只需要使用TREATAS函数修改下日期派生列的数据沿袭即可,如下图所示:
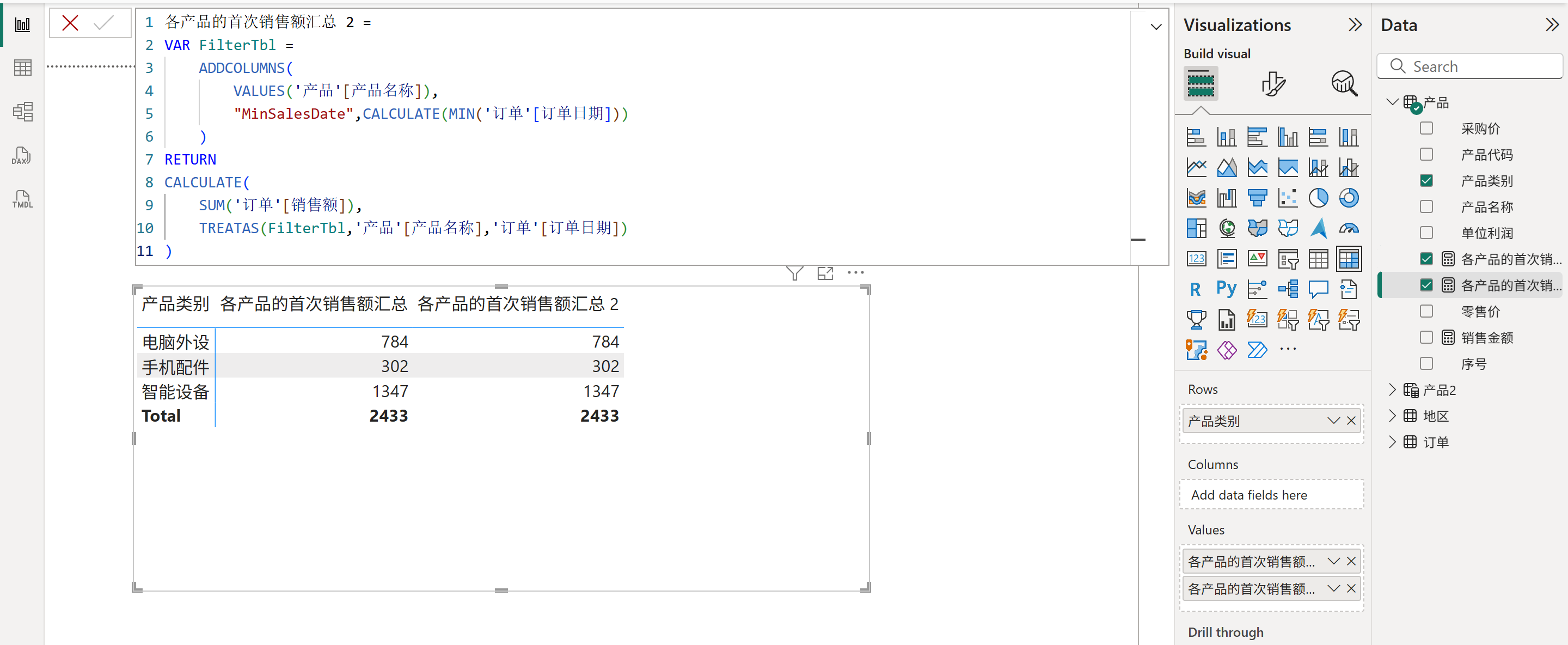
当日期的数据沿袭被修复后,就可以得到正确结果,而且与第一个方法相比,少了一次行上下文转换的开销,性能更好。
总结
数据沿袭是筛选器在DAX这个筛选世界中的通行证,没有数据沿袭的匿名筛选器则无法筛选模型中的任何表。虽然DAX引擎采用了比较巧妙的设计,让我们通常不需要考虑数据沿袭,但在编写表达式时最好还是注意下数据沿袭是否正确,以免无法出现意想不到的错误。

















