
之前有写过文章来介绍如何读取并合并SharePoint上的Excel文件,但考虑到CSV文件也挺常使用,特别是大数据量导出场景下基本都是CSV格式的,因此本篇文章也介绍一下如何读取并合并SharePoint上的CSV文件。
读取单个CSV文件
使用CSV文件的网络路径
1、在SharePoint上找到对应CSV文件,查看其详细信息,然后点击路径隔壁的按钮即可获取到网络路径,如下图所示:
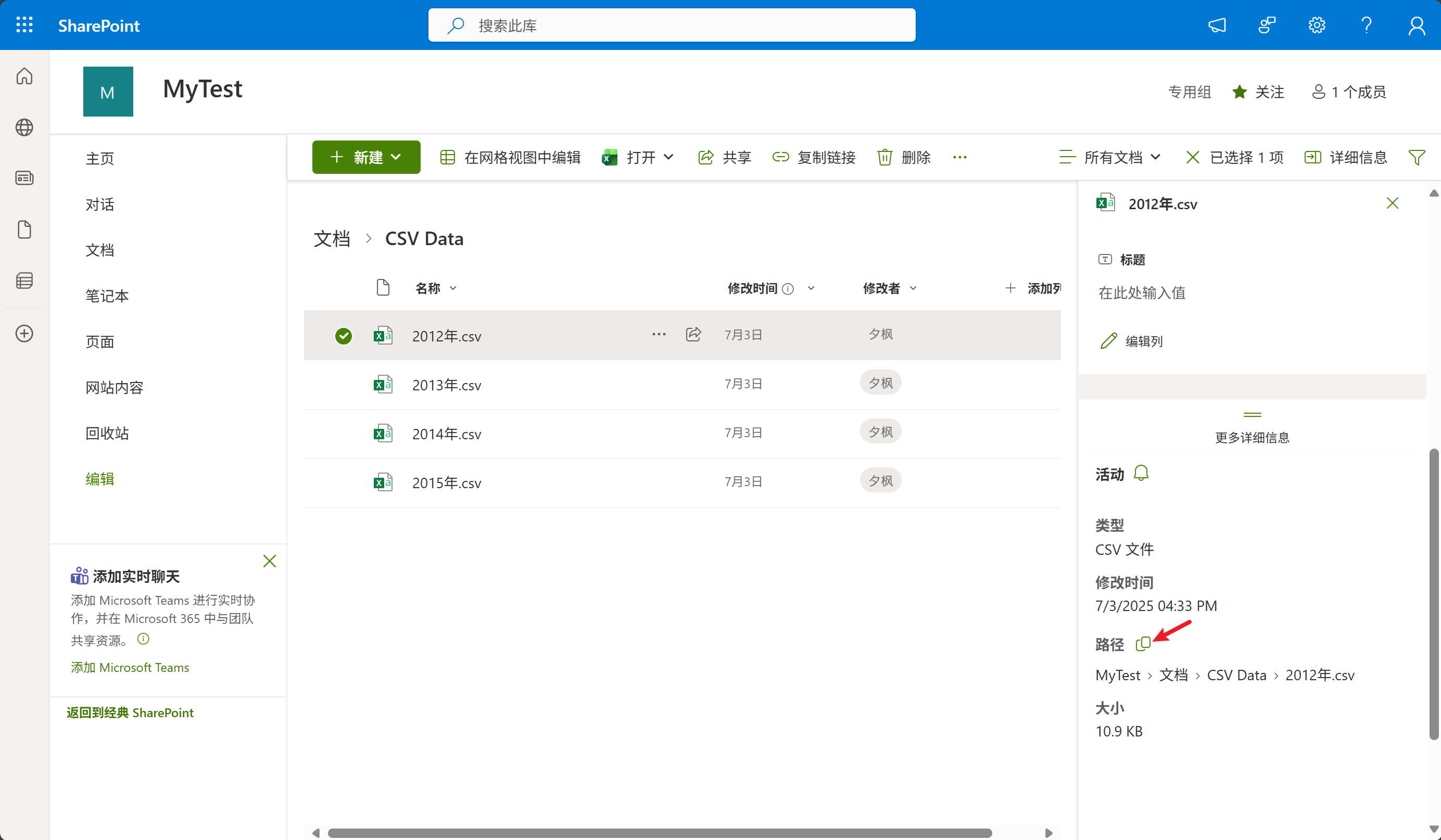
2、在PowerQuery中新建空查询,将以下代码粘贴到高级编辑器,并修改相关参数即可
let
CSVFileUrl = "CSV文件的网络路径",
Source =
Table.PromoteHeaders(
Csv.Document(
Web.Contents(CSVFileUrl),
[Delimiter=",",Encoding=65001] // 如果出现乱码,可将编码改成936
)
)
in
Source注意:该方式只需要有对应CSV文件的访问权限即可,是读取单个CSV文件时的最佳方案。
使用CSV文件的SharePoint路径
1、在SharePoint上找到对应CSV文件,然后从浏览器上方地址栏处截取CSV文件所在的SharePoint站点的链接,SharePoint站点链接的格式为:"https://TenantName.sharepoint.com/sites/SiteName"
2、查看CSV文件的详细信息,记录SharePoint路径,路径从文档开始,如下图所示:
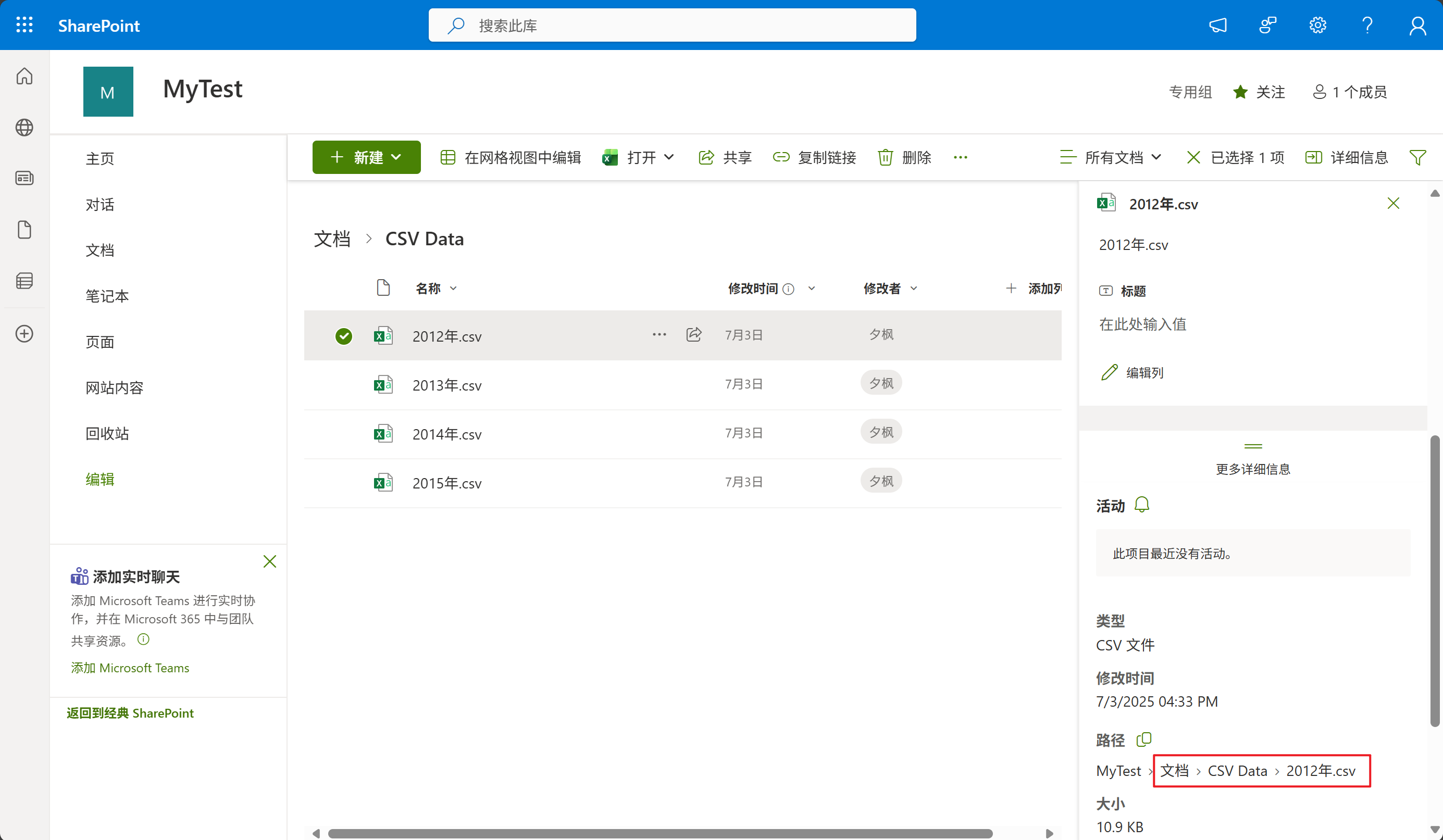
最后,再把文档替换成英文,即:Shared Documents,再把分隔符改为斜杠或反斜杠即可得到完整路径。如上图所示的CSV文件的完整路径应该为:Shared Documents/CSV Data/2012年.csv
3、在PowerQuery中新建空查询,将以下代码粘贴到高级编辑器,并修改相关参数即可
let
SharePointSiteUrl = "https://TenantName.sharepoint.com/sites/SiteName", // 此处填写SharePoint站点链接
FolderPath = "Shared Documents/CSV Data/2012年.csv", // 此处填写CSV文件的SharePoint路径
RootContents = Table.Buffer(SharePoint.Contents(SharePointSiteUrl,[ApiVersion="Auto"])),
Source = List.Accumulate(Text.SplitAny(FolderPath,"/\"),RootContents,(r,c)=>r{[Name=c]}?[Content]?),
CSVData = Table.PromoteHeaders(Csv.Document(Source,[Delimiter=",",Encoding=65001])) // 如果出现乱码,可将编码改成936
in
CSVData注意:该方式需要有对应CSV文件及其所有上级文件夹的访问权限,仅有CSV文件的访问权限并不够。
合并文件夹下的所有CSV文件
使用文件夹的网络路径
1、在SharePoint上找到对应文件夹,然后从浏览器上方地址栏处截取文件夹所在的SharePoint站点的链接,SharePoint站点链接的格式为:"https://TenantName.sharepoint.com/sites/SiteName"
2、查看文件夹的详细信息,然后点击路径隔壁的按钮即可获取到网络路径,如下图所示:
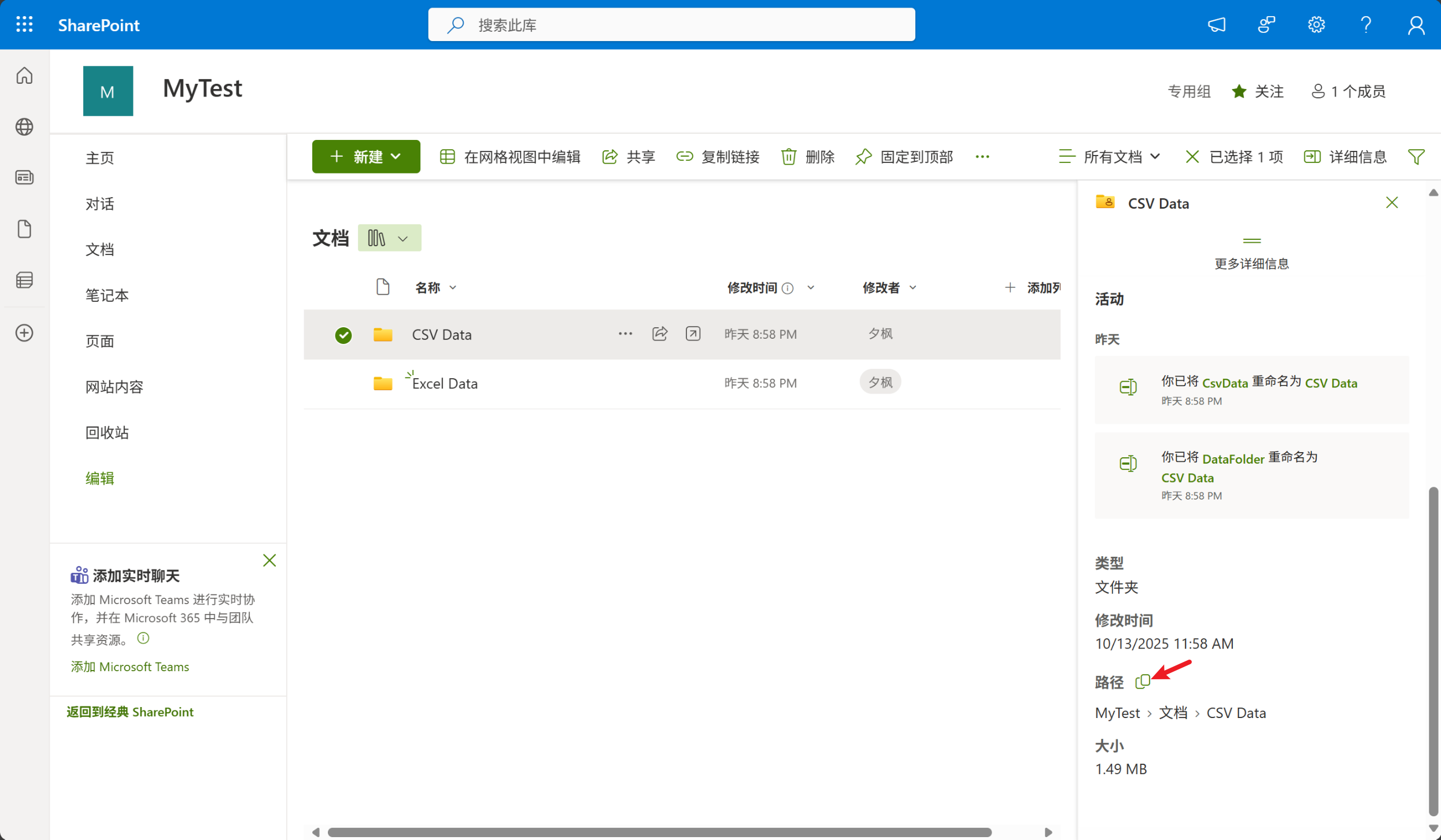
3、在PowerQuery中新建空查询,将以下代码粘贴到高级编辑器,并修改相关参数即可
let
SharePointSiteUrl = "https://TenantName.sharepoint.com/sites/SiteName", // 此处填写SharePoint站点链接
FolderPath = "https://TenantName.sharepoint.com/sites/SiteName/FolderPath", // 此处填写文件夹的网络路径
RootContents = Table.Buffer(SharePoint.Files(SharePointSiteUrl,[ApiVersion="Auto"])),
Source = Table.SelectRows(RootContents,each [Folder Path]=Uri.Parts("a?a="&FolderPath&"/")[Query][a]),
CsvData =
Table.RenameColumns(
Table.AddColumn(
Table.SelectRows(Source,each [Extension]=".csv"),
"csv",each Table.PromoteHeaders(Csv.Document([Content],[Delimiter=",",Encoding=65001])) // 如果出现乱码,可将编码改成936
)[[Name],[csv]],
{{"Name","FileName"}}
),
AddFileName = Table.ToList(CsvData,each Table.AddColumn(_{1},"FileName",(x)=>_{0})),
Result = Table.Combine(AddFileName)
in
Result注意:该方式只需要有对应文件夹的访问权限即可,适合文件数量较少的站点或只有对应文件夹权限时使用。
使用文件夹的SharePoint路径
1、在SharePoint上找到对应文件夹,然后从浏览器上方地址栏处截取文件夹所在的SharePoint站点的链接,SharePoint站点链接的格式为:"https://TenantName.sharepoint.com/sites/SiteName"
2、记录文件夹的SharePoint路径,路径从文档开始,如下图所示:
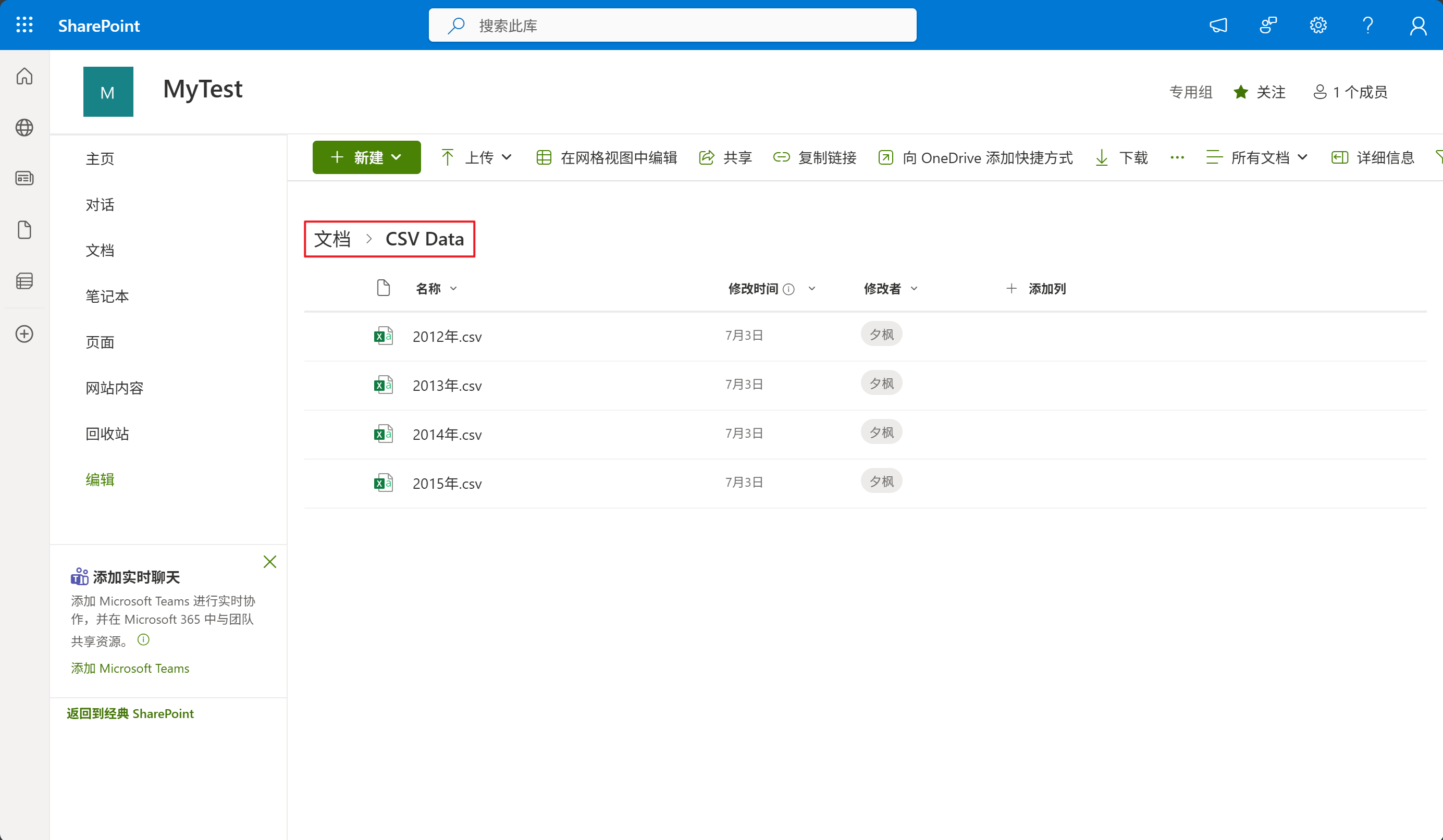
最后,再把文档替换成英文,即:Shared Documents,再把分隔符改为斜杠或反斜杠即可得到完整路径。如上图所示的文件夹的完整路径应该为:Shared Documents/CSV Data
3、在PowerQuery中新建空查询,将以下代码粘贴到高级编辑器,并修改相关参数即可
let
SharePointSiteUrl = "https://TenantName.sharepoint.com/sites/SiteName", // 此处填写SharePoint站点链接
FolderPath = "Shared Documents/CSV Data", // 此处填写文件夹的SharePoint路径
RootContents = Table.Buffer(SharePoint.Contents(SharePointSiteUrl,[ApiVersion="Auto"])),
Source = List.Accumulate(Text.SplitAny(FolderPath,"/\"),RootContents,(r,c)=>r{[Name=c]}?[Content]?),
CsvData =
Table.RenameColumns(
Table.AddColumn(
Table.SelectRows(Source,each [Extension]=".csv"),
"csv",each Table.PromoteHeaders(Csv.Document([Content],[Delimiter=",",Encoding=65001])) // 如果出现乱码,可将编码改成936
)[[Name],[csv]],
{{"Name","FileName"}}
),
AddFileName = Table.ToList(CsvData,each Table.AddColumn(_{1},"FileName",(x)=>_{0})),
Result = Table.Combine(AddFileName)
in
Result注意:该方式需要有对应文件夹及其所有上级文件夹的访问权限,仅有对应文件夹的访问权限并不够,适合具有整个站点权限时使用。
总结
如果需要读取与合并的不是CSV文件,而是其它文件,那么只需要修改解析函数即可,比如Excel.Workbook可以读取Excel文件,Json.Document可以读取JSON文件等等。



















